联邦迁移学习分享(一)
现有的联邦学习方法(横向和纵向联邦学习)要求所有的参与方具有相同的特征空间或样本空间,从而建立起一个有效的共享机器学习模型。
但是,在更多的实际情况下,各个参与方拥有的数据集可能存在高度的差异:
l 参与方的数据集之间可能只有少量的重叠样本和特征;
l 这些数据集的分布情况可能差别很大;
l 这些数据集的规模可能差异巨大;
l 某些参与方可能只有数据,没有或只有很少的标注数据
因此,在这样的背景下,我们探索联邦迁移学习以解决上述问题。具体来说,联邦迁移学习指的是结合联邦学习和迁移学习的相关技术,使其可以应用于更广的业务范围,同时可以帮助只有少量数据(较少重叠的样本和特征)和弱监督(较少标记)的应用建立有效且精确的机器学习模型,并且遵守数据隐私和安全条例的规定。
首先给出问题定义:
现有的联邦学习方法要求所有的参与方具有相同的特征空间或样本空间以进行横向或者纵向的联邦学习,但是在很多情况下,各个参与方只有少量的样本和特征重叠。比如金融和零售领域,金融领域有用户的属性数据、借贷数据等,而零售领域有大量用户行为数据、线下购买消费记录等。对于一些金融领域的企业来说,由于在信贷业务应用中存在数据稀缺、不全面、历史信息沉淀不足等问题,当在进行具体信贷工作时,或需构建信贷相关模型时,因数据样本少,可能存在冷启动的问题,无法进行应用。
问题目标:在保证数据安全的情况下,将其他领域的知识迁移到目标领域,以提升目标领域的模型准确率。
问题形式化:
已知:
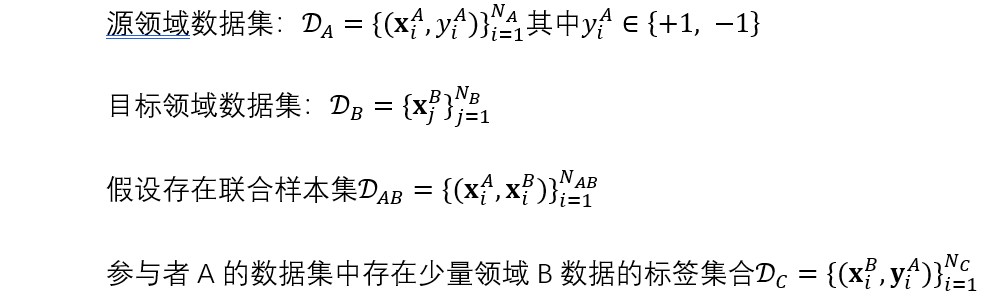
目标:
最小化目标领域的预测误差
研究方法:
针对以上问题,首先给出联邦迁移学习(FTL)的损失函数定义,再引入同态加密算法保证FTL过程的隐私与安全性。
FTL框架:

同态加密:
具体系统框架图如下:
参考文献
[1] Liu Y, Kang Y, Xing C, et al. A secure federated transfer learning framework[J]. IEEE Intelligent Systems, 2020, 35(4): 70-82.
- 发表于 2023-02-13 11:00
- 阅读 ( 2706 )
- 分类:群智能体知识迁移
