强化学习论文分享--UPDeT
UPDeT: Universal multi-agent reinforcement learning via policy decoupling with transformers
论文链接:https://arxiv.org/pdf/2101.08001
代码链接:https://github.com/Theohhhu/UPDeT
发表会议:2021 ICLR
摘要
一般来说,当前MARL(Multi-Agent Reinforcement Learning 多智能体强化学习)训练模式是:每个模型要从零开始训练。比如《星际争霸2》3m vs 3m 和5m vs 6m必须要分别训练,原因是模型的input和output是固定维度的,学习到的经验无法被积累、迁移到新的模型。本篇论文探索一个通用的、可满足多种需求的多智能体框架(UPDeT)。不同于RNN,我们利用基于Transformer的模型,解耦了输出策略分布和输入观察(observation,简称obs),生成了灵活的决策。对比标准的Transformer,我们进一步放松了动作空间维度限制,可解释性也更高。它在MARL中泛化性更好,一次训练可以同时处理多个任务。在更大规模的MAgent环境中实验结果表明,它比传统的算法在性能和训练速度上都提升了10倍。
研究背景
团队协作是多智能体强化学习领域的研究热点
- 通常,MARL方法限制在固定数量的智能体
- 针对不同任务的模型需要从零开始训练
- 学习到的经验无法被积累、迁移到新的模型
现有动作值函数模型表现能力差
- 将环境中不同实体的观察视为整体的组成部分
- 默认神经网络可以自动解耦观察和策略
- 忽略了每个动作背后的物理意义
研究目标:开发一个不限制输入/输出维度、具有通用性、可解释的,可以优化单任务场景最终性能,多任务场景可以做迁移学习的MARL算法
模型概览
受到Self-Attention机制的启发,提出了基于Transformer的算法,取名叫UPDeT,该算法有以下四个优点:
- 训练好以后,可以四处部署
- 策略解耦后算法表达能力更健壮
- 算法可解释性更强
- 可以泛化在任何MARL领域
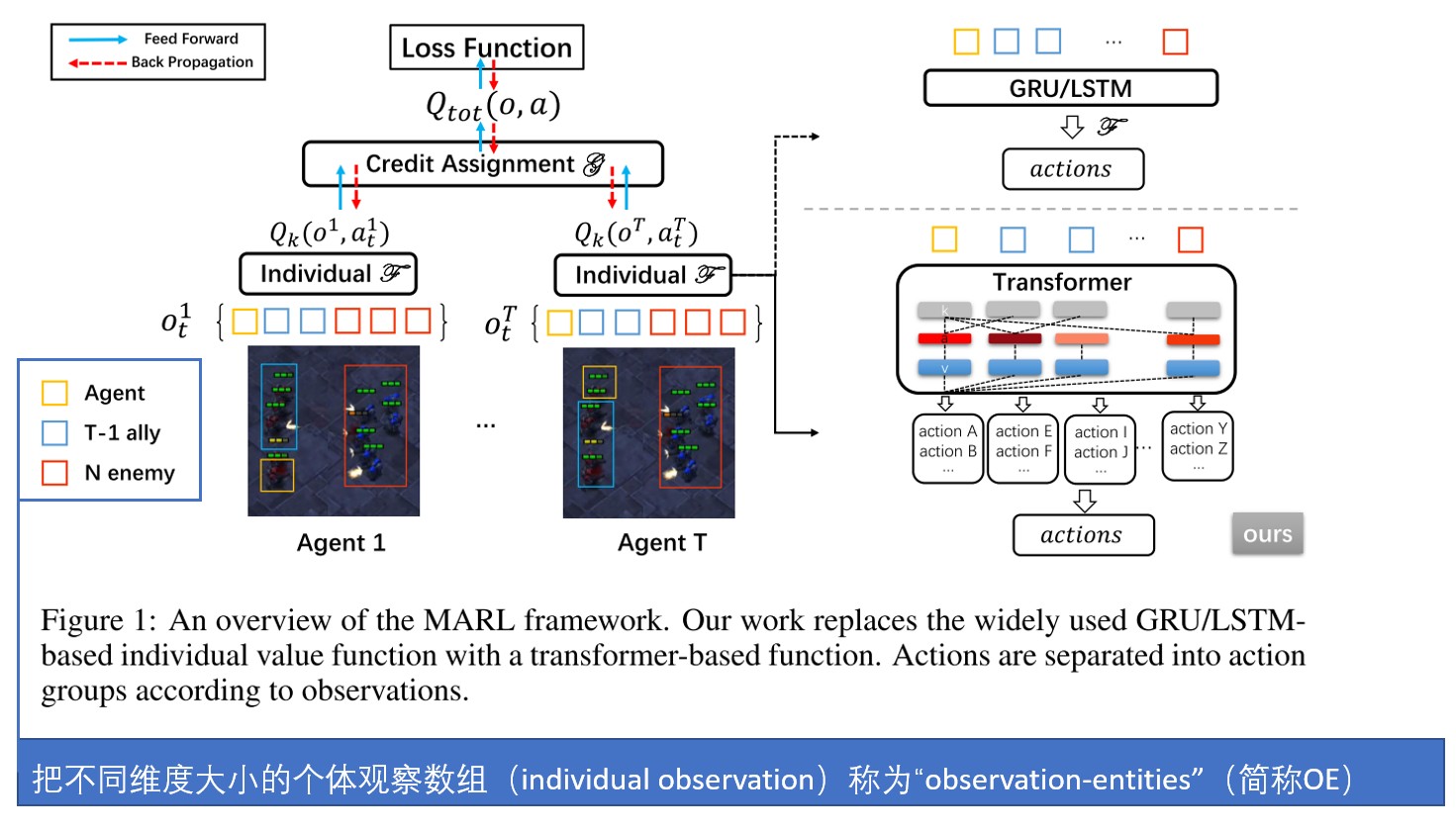
策略解耦的具体办法是:
用Transformer函数来处理OE。接着依据动作和OE的对应关系,把动作空间划分成多个action-group(简称AG)。这样我们就得到了OE-AG Pair。
下一步,用Self-Attention学习Pair中的OE和其他OE的关系。通过使用self-attention map和对OE的embedding操作,**UPDeT框架在action-group级别优化策略。这就是策略解耦**。结合了策略解耦和Transformer的UPDeT框架显著优于传统RNN。
在UPDeT算法中,不需要为新的任务引入新的参数。我们还证明了**有且仅有**在OE与AG相匹配的解耦策略下UPDeT框架才能学到具有高迁移能力的强表征。最后,我们建议把UPDeT算法插入您现有的算法中,不需要改变整体结构也能够带来显著的最终性能提升,尤其在业务场景复杂情况下。
具体方法
基于transformer的个体Q函数
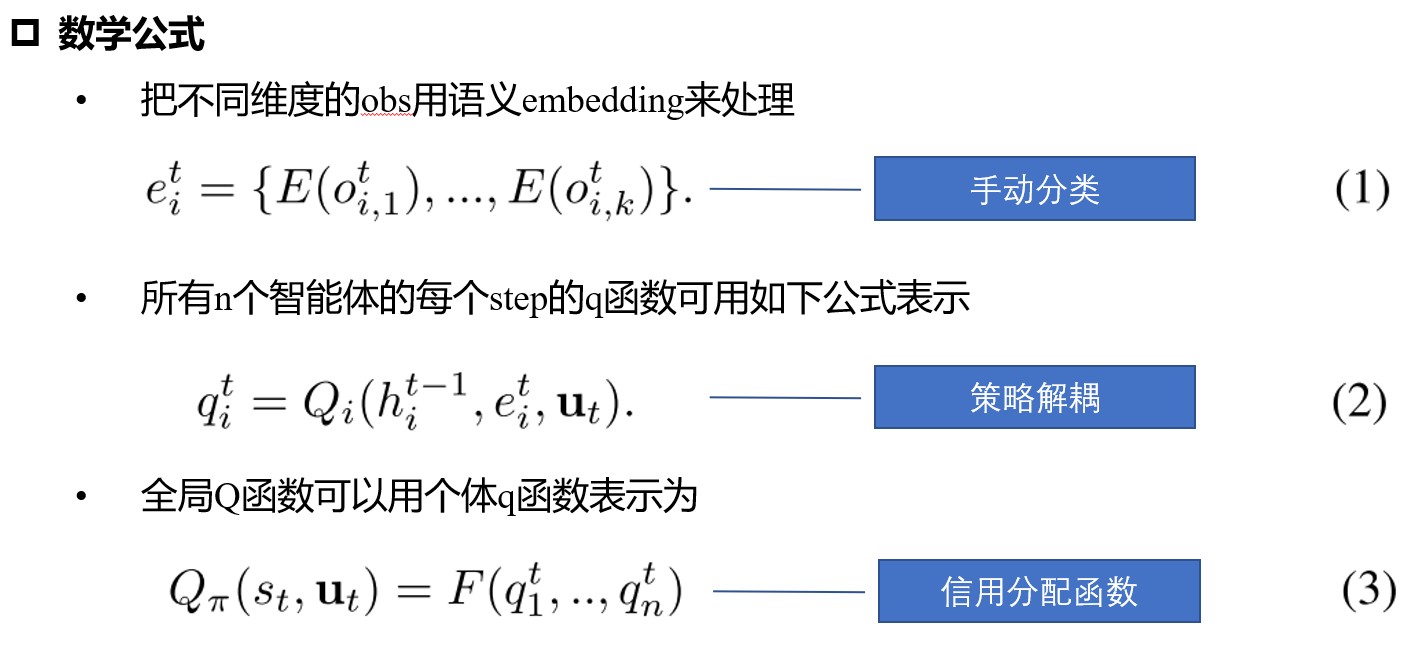

策略解耦
策略解耦P函数的三大目标:
- AR – 不限制动作策略维度 标准的transformer的约束是:输出维度要小于等于输入维度。这在MARL中是不能接受的,因为动作空间可能大于entity空间。
- MA – 模型一次可处理多个任务 需要相对固定的网络结构而不是引入新的参数,不幸的是这跟第一点难以两全的。
- EXP – 模型可解释性提升 用解释性更好的策略生成网络替代RNN。
基于上面三个原则,相应提出了三种策略解耦方法,分别取名叫做Vanilla(原始),Aggregation(聚合) 和 Universal(UPDeT)。如下图:
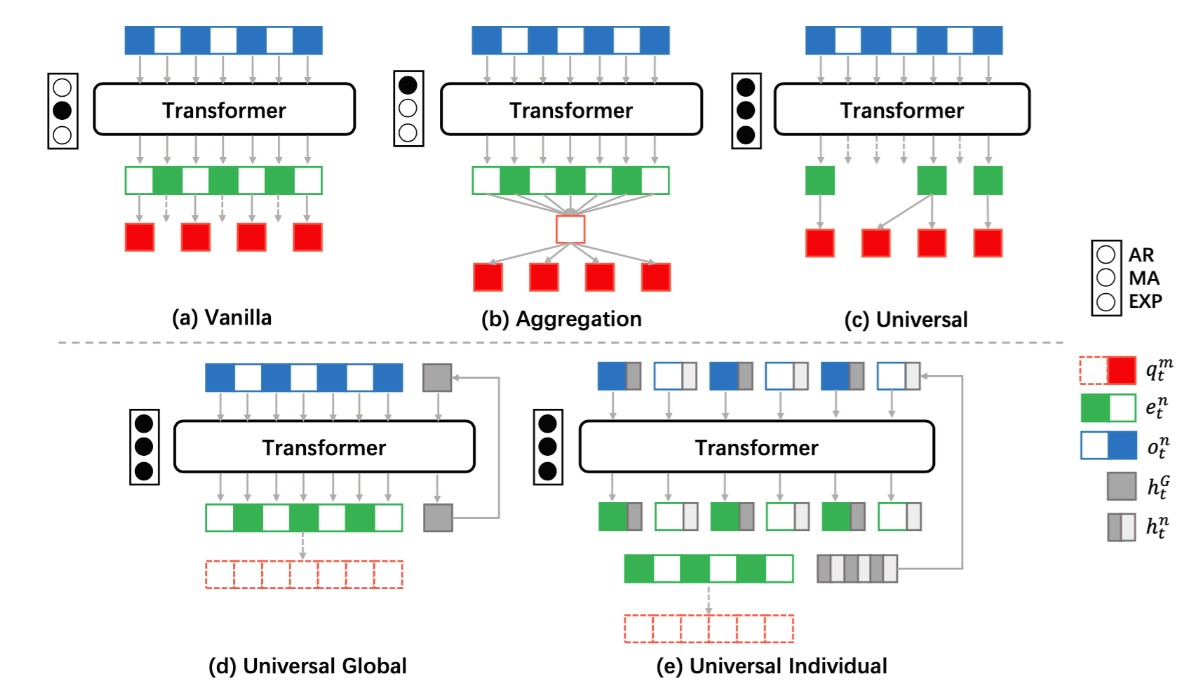
上面3个图是策略解耦的三种实验。 下面2个是时间单元的两种实验。
符号含义:AR:动作空间限制。 MA:一次执行多个任务。 EXP:可解释性 (黑点表示满足对应原则)
UPDet首先的想法是将输入OE和对应的动作(output policy part)匹配。这种情况在MARL中很常见,比如两个agent交互(协作或者竞争)。一旦我们匹配上了特征OE和动作,我们可以大大减少用self-attention学习表征的算力负担。另外,考虑到一个OE可能关联多个动作,我们把动作空间切分成动作组(AG),和OE关联的动作都放到一个AG组里。处理流程请看*下图左边*。为了满足上面的第1,2个原则,我们设计的映射函数考虑了2个策略:
- 如果动作组的动作大于1个会增加一个共享的全连接层将输出映射到动作编号维度
- 如果特征没有对应的动作组,直接抛弃
这两点请看下图右边。显而易见,UPDet算法既没有限制动作维度,又没有引入新的参数。一个模型就可以处理不同的任务。那么关于上面的原则3,映射函数匹配相应的特征和动作组即可满足原则3。
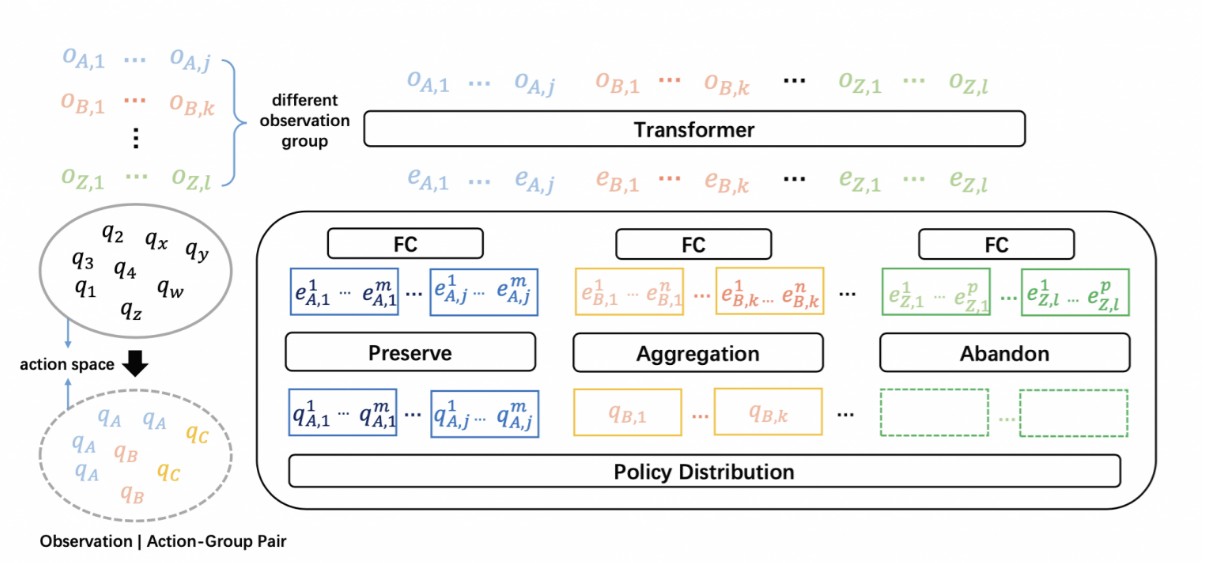
左边的含义:把q分成了a,b,c三个组(自己,盟友,敌人)
右边的含义:把Observation通过Transformer转换成了Embedding,然后把Embedding映射到Policy。映射内部有丢弃(abandon)、聚合(aggregation)、保留(preserve)三种操作。
实验
文章用星际争霸2环境评估算法UPDeT。对比了在单一任务场景下对比传统RNN算法和UPDeT算法,同时测试UPDeT模型的迁移能力。实验结果表明UPDeT有显著提升。
- 发表于 2023-02-13 15:23
- 阅读 ( 2856 )
- 分类:群智能体知识迁移
