强化学习论文分享--整合的层级化强化学习
Intelligent problem-solving as integrated hierarchical reinforcement learning
论文链接:https://arxiv.org/pdf/2208.08731
发表会议:Nature Machine Intelligence, 2022
摘要
认知心理学和相关学科指出,生物智能体解决复杂问题的能力的发展,依赖于层级化的认知机制。层级化强化学习(hierarchical reinforcement learning)是一种很有前景的计算方法,最终可能会在人工智能和机器人身上产生类似的解决问题的能力。然而,至今为止,许多人类和非人类动物的解决问题的能力显然优于人工系统。在本文中,我们提出了将受生物启发的层级化认知机制整合起来的几个步骤,来赋予人工智能体先进的解决问题技能。我们首先回顾了认知心理学的文献,强调组合式抽象( compositional abstraction)和预测处理(predictive processing)的重要性。然后,我们将所获得的见解与当代的层级化强化学习方法联系起来。有趣的是,我们的研究结果表明,所识别的所有认知机制,都已经在不同的计算架构中分别实施过了。这便引出了一个问题:为什么没有一个统一的架构去集成它们?对该问题的回答是本文最后一个贡献。我们提供了一个新的综合的视角,来说明形成这样一个统一的结构,需要解决的计算性挑战。我们希望该综述能够引导受更复杂的认知结构启发的层级化机器学习架构。
背景
人类和其它智慧动物,能够将复杂问题拆解为简单的、之前学过的子问题。这种层级化的方式,使他们能够一次解决之前没有遇到的问题,即,不需要任何试错。例如,图1描述了乌鸦是如何采用3个有因果连接的步骤,解决了一个复杂的食物获取难题的:它首先捡起一个棍子,之后用棍子获得石头,最后使用石头触发机关释放食物。

图1:一只新喀里多尼亚乌鸦解决了一个获取食物的问题
启发:我们如何能够让智能体和机器人,也具有类似的层级化学习和零样本问题解决(zero-shot problem-solving)的能力呢?
本文主要内容:
- 我们评估了层级化决策的神经认知基础,并识别出使高级问题解决能力得以实现的重要机制。
- 我们揭示了当前的层级强化学习方法的整合问题,指出大部分已被实现的生物学机制,都是以孤立而非整合的方式实现的。
- 我们指出整合关键方法和机制的步骤,以克服上述整合问题,发展一个统一的认知框架。
神经认知基础
下文指出:生物体的复杂的问题解决技能,可以用几种特定的认知能力清晰描述,这些能力依赖于几项核心认知机制,包括抽象(abstraction),内在动机(intrinsic motivation)和心智模拟(mental simulation)。图2展示了这些机制如何在前向或逆向的模型(作为神经活动的先决条件)中发展出来。
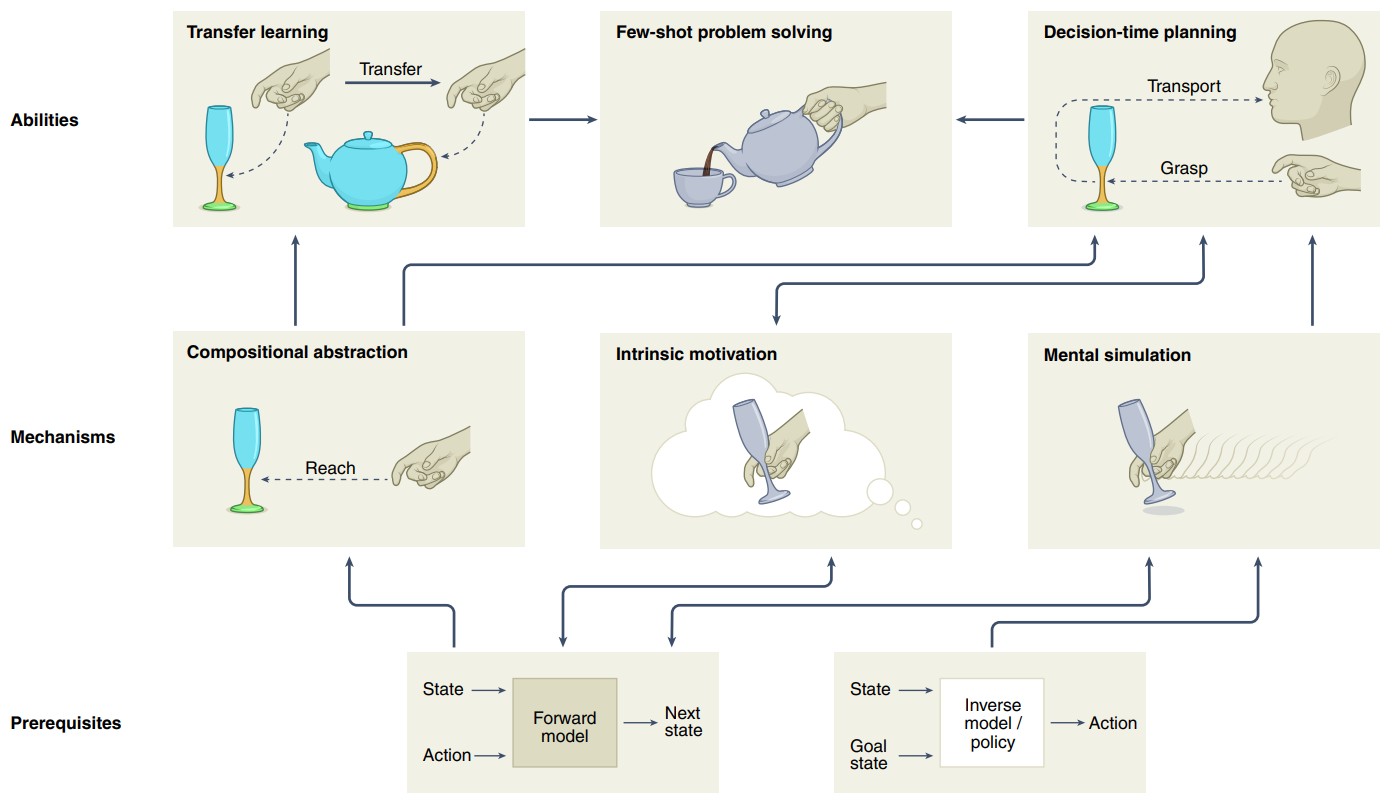
图2. 生物体解决问题的先决条件、机制和特征。
前向和反向模型是高阶认知机制和能力的先决条件。组成式抽象,允许智能体将问题分解为可复用的子结构,例如,学习到物体的哪一部分是易于抓取的,比如玻璃杯的杯颈。在前向模型的帮助下,内在动机可以驱动智能体,以一种搜索信息的、认知的方式与环境互动。例如,内在动机引导智能体与杯子互动,来了解杯子特征。心智模拟使得探索可能的状态-行为顺序成为可能,例如,想象伸向玻璃杯的手的位置将如何演变。在上述机制的帮助下,智能体能够经由层级化的、组合式的目标驱动规划,灵活地达到想要的状态,例如,喝水的规划是先正确地抓取杯子,再妥当地移动杯子。组合式抽象使得智能体能够进行迁移学习,例如,像抓取其它有柄的物体(如茶壶)一样,去适当地抓取杯杯颈,从而使小样本问题解决成为可能。
认知能力
我们关注认知能力的以下特征和性质:
小样本问题解决(Few-shot problem-solving):小样本问题解决,指在少于5次的尝试下,解决未知问题的能力。而零样本问题解决,是小样本问题解决的一种特殊情况,指不需要额外尝试即可解决新问题。例如,在之前解决过相关问题,但没有经过进一步训练的情况下,乌鸦可以使用木棍作为工具,解决全新的食物获取问题(图1)。我们指出,要这样解决问题,有两种能力至关重要:迁移学习(transfer learning)和决策时规划(decision-time planning)。
迁移学习:迁移学习允许生物体将之前任务的解法,迁移到一个新的但相似的任务上,从而使小样本的问题解决成为可能。这显著地减少了,有时甚至消除了解决一个新问题所需要尝试的次数。
目标导向的规划(goal-directed planning):动作生成的观念运动(Ideomotor)理论指出,预期动作的效果决定了动作的选择。与此相对应,事件编码(event encoding)理论指出,一个动作的表征和它们的效果存储在共享的编码中,对动作-效果的预期,可以直接激活相关动作的编码。
迁移学习和规划的认知机制
前文讨论了迁移学习和规划能力是如何让智能体具有小样本问题解决能力的。但是什么使迁移学习和规划能力成为可能的?我们的调研指出,迁移学习和规划所需的三种认知机制是感觉运动抽象(sensorimotor abstraction),内在动机(intrinsic motivation)和心智模拟(mental simulation)。
感知运动的抽象。感觉动作的组合抽象及奠基。层级化强化学习,具有时序和表征两个维度,还能区分动作和状态的抽象。对动作的时序抽象,将复杂的问题分解为层级化的简单问题。影响力最大的表征动作抽象方法,是基于行为基元构建的,其中包括了选择、次级策略和原子化的高层级技能。这些行为基元位于一个抽象的表征空间中,例如,在一个充满动作标签和索引的离散有限空间中。而较为新进的高层级动作表征,则是由低层级的状态空间中的子目标所构成。在这里,智能体通过完成一系列子目标,来实现最后的目标。
内在动机。通过设立内在动机的目标,内在动机影响着目标导向的归因。从认知发展的角度来看,内在动机这个术语,是用来描述‘搜索新事物……探索,学习的内在倾向’的。内在动机引出了一般的探索行为,好奇心和嬉戏。好奇心指以收集信息为目标的探索行为。好奇心和嬉戏密切相关,后者是以提高技能为导向的新奇互动。在多种智慧动物中,都可以观察到嬉戏行为,例如狗和乌鸦。
心智模拟。心智模拟,指的是智能体能够在多种表征层面,预测环境动态的能力。例如,人们认为,动作想象使得运动员能够通过在内心模拟这个运动动作,来改进对高难度身体动作(例如倒翻转)的执行,工程师在开发机械系统时,也依赖心智模拟。
计算实现
层级化强化学习的一系列机制在计算机中的实现(如图3)并不像在生物体中整合得那么好。下文将概述当前最先进的,与神经认知基础相关的计算实现方式。
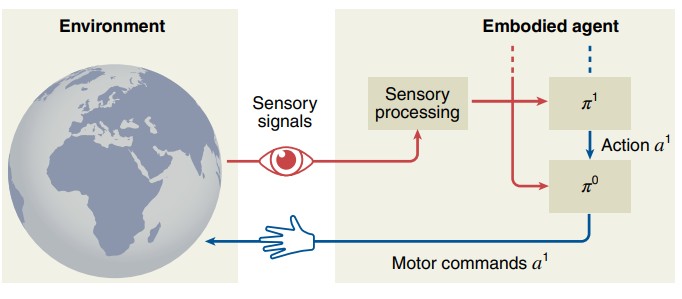 图3. 通用的层次化问题解决架构。
图3. 通用的层次化问题解决架构。
我们对神经认知基础的调研指出,迁移学习和规划,是小样本问题解决的两项基础认知能力。但我们如何在计算上对它们进行建模呢?
迁移学习。迁移学习对于层级化架构来说是很自然的,因为该架构可以复用高层级的通用技能,将它们用在不同的低层级任务上,反之亦然。因此,在当前迁移学习中,有很大比例的方法是建立在复用低层级策略上的。研究者不仅考虑了在不同任务间的,也考虑了在不同机器人,即不同形态的智能体之间的迁移学习。
规划。规划可分为决策时规划和后台规划(background planning)。决策时规划指搜索一系列动作,来决定为达成特定目标,接下来要采取什么动作。搜索是通过用特定领域的动力学的内部预测模型模拟动作来实现的。决策时规划,使零样本问题解决成为可能,因为智能体只在内部预测模型指出动作能达成预期目标时,才会执行规划的动作。后台规划,是Sutton提出的一种基于模型的强化学习方法。它使用前向模型模拟动作,来训练得到特定策略。这可以提高采样效率,但还不足以使小样本的问题解决成为可能。
在传统的人工智能中,层级化的决策时规划是一个广为人知的范式,但将它和层级化的强化学习结合的方法却很罕见。有些方法会通过基于动作规划的高层级的决策,和基于强化学习的低层级的动作控制,将动作规划和强化学习结合。这些方法证明,决策时规划对于离散状态-动作空间中的高层级推断格外有用。
- 发表于 2023-02-13 16:15
- 阅读 ( 2371 )
- 分类:群智能体知识迁移
