背景融合的虚拟形象生成方法
生成姿态与服饰可控的人体图像是塑造虚拟形象的一个关键技术。除此之外,将生成出的虚拟形象合理放置在不同的背景图片也是提升交互性与真实感的一个步骤。为此,本文主要探讨如何将人体图像与场景图像进行组合。
为了合理地将人体与背景进行高质量的无缝衔接,合成出具有高质量视觉效果、符合物理和成像规律的图像,需要考虑以下两方面的融合:
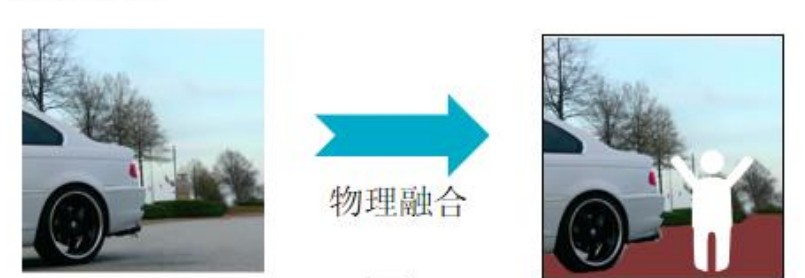
(1)物理融合:生成的人物应处在符合物理规律的位置;例如,应该将人物放置在空旷的地面上;
(2)视觉融合:的人物应与背景产生一致的光线与色彩,例如,在光线较暗的傍晚时人体应该是暗的;
为了实现上述两个层次的融合,采用以下方案:
(1)物理融合:首先,使用DeepLab V3语义分割算法找到场景图中地面区域,取面积最大的连通区域作为目标地面,将人物放置在该地面上。因为大面积的地面意味着,该处上方没有其他物体遮挡,可以在一定程度上避免人与背景间的重叠。其次,为了突出人物主体,计算目标区域的质心(x, y),然后将质心向下移动至区域的边缘,得到基准点(x', y')。此时,通过将人体图像底部中点与基准点(x', y')对齐来放置人体,并通过图像缩放操作来改变人体大小使其充满整个背景图。
制掩码。视觉融合网络为编码器-解码器网络,并且在编码器和解码器之间添加了跳跃式连接,使得网络可以在解码阶段更好的访问背景特征。网络的输出为调整过颜色和边缘的最终人体场景图像。

经过上述两个步骤,可以得到人体与场景自然组合的图像,下面是一些生成案例:

- 发表于 2023-02-13 23:05
- 阅读 ( 1112 )
