基于YOLOv5的飞机目标检测
1 引言
1.1 研究背景
当今世界,计算机智能化的程度越来越高,而计算机视觉的应用也越来越广泛,从最开始的识别物品到人脸识别的动态观察,计算机能识别的图像越来越复杂化,动态化,模糊化,这都离不开深度学习算法:计算机通过大量的训练也可以完成人类依靠经验才能做出的判断。而人类对于大量相似图片的识别能力往往是有限的,而且在经过一段时间的工作之后,效率和准确度都会有一定程度的下降,但是计算机只会在训练中不断地提升自己的识别能力,所以计算机在模式识别方面具有后发制人的优势。
人类正在进入信息时代,计算机将越来越广泛地进入几乎所有领域。而且越来越深入人们的日常生活,智能计算机能帮助人类完成的工作也越来越多。人可通过视觉和听觉,来与外界交换信息,并且可用不同的方式表示相同的含义,而目前的计算机却要求严格按照各种程序语言来编写程序,只有这样计算机才能运行。为了让计算机的使用更加的便捷,必须改变过去的那种让人来适应计算机,来死记硬背计算机的使用规则的情况。我们需要让计算机来适应人的习惯和要求,以人所习惯的方式与人进行信息交换,也就是让计算机具有视觉、听觉和说话等能力。这时计算机必须具有逻辑推理和决策的能力。具有上述能力的计算机就是智能计算机。
计算机视觉就是用各种成象系统代替视觉器官作为输入敏感手段,由计算机来代替大脑完成处理和解释。计算机视觉的最终研究目标就是使计算机能象人那样通过视觉观察和理解世界,具有自主适应环境的能力。要经过长期的努力才能达到的目标。因此,在实现最终目标以前,人们努力的中期目标是建立一种视觉系统,这个系统能依据视觉敏感和反馈的某种程度的智能完成一定的任务。
现在人们对于计算机的要求也越来越高,比如高速路上的无人驾驶技术就需要迅速对目前的图像做出识别与判断,因为车辆在行驶中速度很高,所以就需要很高的判断速度和准确度,越高的精度和速度就需要越高的技术,因此研究这类问题是很有必要的。
1.2 现实意义
我们小组使用YOLO模型来训练计算机获得识别飞机的能力,如果飞机能够被迅速而准确的识别将对我们产生巨大的帮助。
首先,当今国际局势紧张,局部冲突经常发生,而战斗双方往往会派出大量的无人机进行侦查,这些无人机如果能够被迅速发现并击落就可以有效防止敌人探查我方情况,同时也可以使敌方损失一定的侦查力量和士气。如果对方派出了带有隐身能力的飞行器,雷达无法捕获,此时就只能依靠图像识别来确定敌方战机的情况,就更需要迅速对敌方的飞机进行识别与确定,从而进行打击。而我方也可以使用卫星或者直接派出无人机对敌方的阵地进行侦查,如果能够识别出对方的机场甚至能识别出经过伪装的飞机,就能对敌方阵地进行精准打击。
在民用航空方面,如果雷达因为某种原因失效,飞行员也可以通过远距离的图像识别来确定自身航线是否安全。
其次,我们的训练模型虽然只识别了飞机的图片但是如果加入别的训练素材,理论上计算机就可以识别一切图像在医学方面也有很多重要的作用,计算机可以用更高的精确度来进行病人病情的诊断,通过一张CT,计算机可以发现细小的病变从而提高诊断的正确性。在体检时,面对绝大多数都是正常的医学影像,单单用人眼去观察很容易出现失误,而如果用计算机加以辅助,先由计算机通过图片识别确定出一些可能出现问题的图片,再由医生进行进一步的确定,这样既可以提高诊断正确性,更可以减少医生的工作量。
还有一些其他重要的应用领域:
无人驾驶技术,车辆进行自主的视觉导航,目前还没有让机器像人类那样识别和理解环境的技术,目前主要的研究目标是提升在高速公路上的道路跟踪能力,这样可以建立避免与前方车辆碰撞的视觉辅助驾驶系统,让电脑和人脑一起工作,让交通事故发生率进一步降低,电脑和人脑相互补充,在人疲劳或者放松警惕的时候设置最后一道防线。
在边防领域,需要对边境要岸进行实时监控,就可以使用计算机视觉技术来识别特定的目标,如人、车、无人机等,有时候距离较远的肉眼观察,很难发现和辨别,而AI图像处理板卡不仅具备识别监测功能还能对移动的目标进行锁定跟踪。在瞬息万变的现代军事领域,谁能减少作战反应时间,谁就能更好的占据有利的局势,图像处理技术以其精准的识别监控、锁定跟踪的能力,将在未来军事领域有大作为。以中印冲突为例,如果在我国边防境内安装图像识别模块,就能及时侦查到敌军动向,并向后方指挥中心发出告警,这样减少前方和后方的沟通时间,对我国及时应对边境冲突,占据舆论高地、减少人员伤亡具有重要意义。
在远程作战领域,多目标图像识别处理技术还可以用于远程锁定打击。如传统的导弹远程攻击,就可以采用图像处理技术,同时选定多个待打击目标,一次锁定打击多个目标,提升远程打击的效率和精度。在多次战争的验证下,无人机作战已成为现代战场中不可或缺的重要装备,在无人机吊舱中搭载图像处理技术,不仅可以帮助搜集准确、实时的战场情报、实时传输目标图像至后端指挥中心,能够让指挥人员全面感知战场态势,还能进行远程精准打击,此次的俄乌冲突中就有很多类似的实战应用,效果突出。
研究计算机的学习能力和图像识别能力有十分广泛的用途和价值,人工智能的发展,智能计算机的发展都要求计算机能够拥有人类所具有的视觉能力并对收集到的图像进行识别与鉴定,所以我们的研究十分具有价值。
2 理论框架
2.1 目标检测
目标检测是计算机视觉领域的核心问题之一,其任务就是找出图像中所有感兴趣的目标,确定他们的类别和位置。目标检测是一个分类、回归问题的叠加,任务可概括为分类(给定图像,识别目标类别)、定位(给定目标在图像中的位置)、检测(定位目标位置并判断目标类别)、分割(确定每个像素属于哪个目标或场景)。
传统目标检测算法:主要基于手工提取特征,具体步骤可概括为:选取感兴趣区域、对可能包含物体的区域进行特征分类、对提取的特征进行检测。虽然传统目标检测算法经过了十余年的发展,但是其识别效果并没有较大改善且运算量大。
基于深度学习的目标检测算法:主要分为Two Stage和One Stage两种思路。
⑴Two Stage:先预设一个区域,该区域称为Region Proposal,即一个可能包含待检测物体的预选框(简称RP),再通过卷积神经网络进行样本分类计算。该算法的流程是:特征提取、生成RP、分类/回归定位。常见的Two Stage算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN等,其特点是检测精度高,但是检测速度不如One Stage方法高。
⑵One Stage:直接在网络中提取特征值来分类目标和定位。该算法的流程是:特征提取、分类/回归定位。常见的One Stage算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、YOLOv5、SSD、RetinaNet等,其特点是检测速度快,但是精度没有Two Stage方法高。
2.2 YOLOv5
概述:YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。
YOLOv5网络结构图
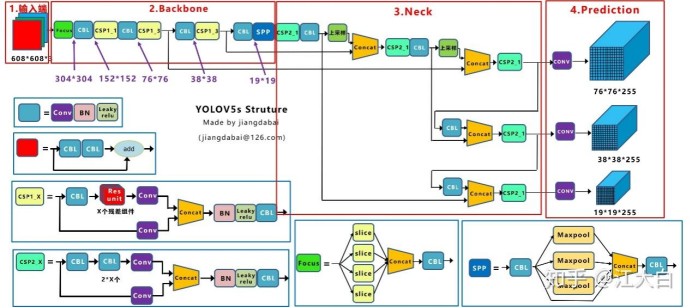
模型构成
⑴输入端
①Mosaic数据增强:将4张图片通过随机缩放、随机裁减、随机排布的方式进行拼接,可以丰富数据集、减少GPU显存。
②自适应锚框计算:针对不同的数据集,设置锚框的初始长宽。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向更新,迭代网络参数。
③自适应图片缩放:不同的图片长宽各不相同,因此将原始图片统一缩放到一个标准尺寸,再送入检测网络中。具体步骤为:计算缩放比例、计算缩放后的尺寸、计算黑边填充数值。
⑵Backbone:特征提取网络,作用是提取图片中的特征信息
①Focus结构:在图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素取得一个值,类似于邻近下采样,这样就得到了四张图片,四张图片互补,且没有信息丢失,这样W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的图片再经过卷积操作,最终得到没有信息丢失的二倍下采样特征图。
②CSP结构:YOLOv5s的CSP结构是将原输入分成两个分支,分别进行卷积操作,使得通道数减半,然后合并两个分支,使得BottlenkCSP的输入与输出大小一致,这样是为了让模型学习到更多的特征。YOLOv5中的CSP有两种设计,分别为CSP1_X结构和CSP2_X结构。
⑶Neck:Neck采用FPN+PAN结构,在目标检测网络中的作用主要是把Backbone提取的特征进行融合,使得网络学习到的特征更具备多样性,提高检测网络的性能。更好地融合/提取Backbone所给出的feature,然后再交由后续的Head。
⑷输出端/head:Head是获取网络输出内容的网络,利用之前提取的特征做出预测。Head可以理解为是根据Backbone提取出来的特征,从这些特征中预测目标的位置和类别。
3 实验过程
3.1 实验环境搭建
⑴Anaconda:用于安装和管理python相关包
⑵Pytorch:构建机器学习环境
⑶PyCharm:python IDE
3.2 数据集准备
⑴数据标注:使用labelme对图像进行标注,保存为json文件
⑵格式转换:将createML标签格式(json文件)转化为yolo标签格式(txt文件)
⑶划分训练集和验证集
3.3 过程展示
⑴从github上克隆YOLOv5源码
⑵安装requirements.txt文件中的依赖
⑶加载预训练权重yolov5s.pt
⑷修改数据/模型配置文件,检测类别数修改为1,类别名修改为airplane,记录存放训练集和验证集的txt文件地址
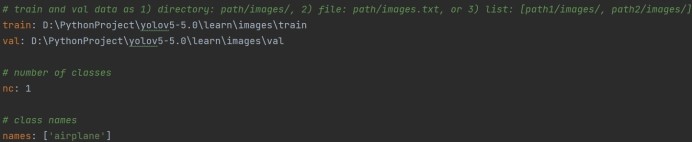
⑸在train.py里设置模型训练轮次(100),根据电脑性能设置输入图片数量与核心数量,开始训练

⑹使用Tensorboard记录训练数据、评估数据
⑺训练完成后,生成runs文件夹,其中results.png和results.txt用于结果分析
⑻在weights文件夹下生成best.pt和last.pt,其中best.pt为最好训练权重,作为后期做推理识别时的权重;last.pt为最后一次训练权重

4 分析讨论
4.1 代码分析
data:存放一些超参数的配置文件,用于配置训练集和验证集的路径,训练自己的数据集时,需要修改对应的yaml文件。
models:包含网络构建的配置文件和函数,s、m、l、x四个版本的检测速度从快到慢,精确度从低到高,训练自己的数据集时,需要修改对应的yaml文件。
utils:存放工具类函数。
⑴create_dataloader函数(datasets.py):train.py中调用该函数创建训练数据集的loader和评估数据集的loader。
⑵torch_distributed_zero_first函数(torch_utils.py):主进程加载数据,其他进程处于等待状态直到主进程加载完数据。该函数在create_dataloader函数中调用,若执行create_dataloader函数的进程不是主进程,则上下文管理器会设置阻塞栅栏,让进程处于等待状态;若是主进程,则直接读取数据并处理。pytroch在分布式训练过程中,对数据的读取采用主进程预读取并缓存,然后其他进程从缓存中读取。
⑶LoadImagesAndLabels类(datasets.py):用于数据读入,该类继承pytorch的Dataset类,需要实现父类的int方法、getitem方法和len方法,在每个step训练时DataLoader迭代器通过getitem方法获取一批训练数据。
⑷load_mosaic函数(datasets.py):Mosaic数据增强是将4张图片通过随机缩放、随机裁减、随机排布的方式进行拼接,可以丰富数据集、减少GPU显存。
⑸ComputeLoss类(loss.py):用于损失计算,其中call方法为每个gt匹配了anchor,以及计算类别损失、定位损失和置信度损失。
weights:存放训练好的权重参数。
detect.py:利用训练好的权重参数进行目标检测。
train.py:存放用于训练数据集的函数。
test.py:存放测试训练结果的函数。
requirements.txt:包含YOLOv5项目环境的依赖,可利用该文本导入相应包。
4.2 结果分析
confusion_matrix.png指的是混淆矩阵(Confusion Matrix),在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。这里得到的结果在下图
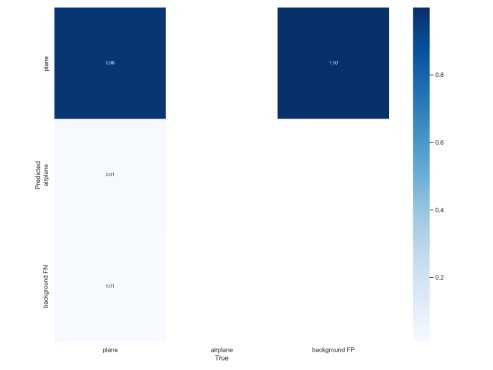
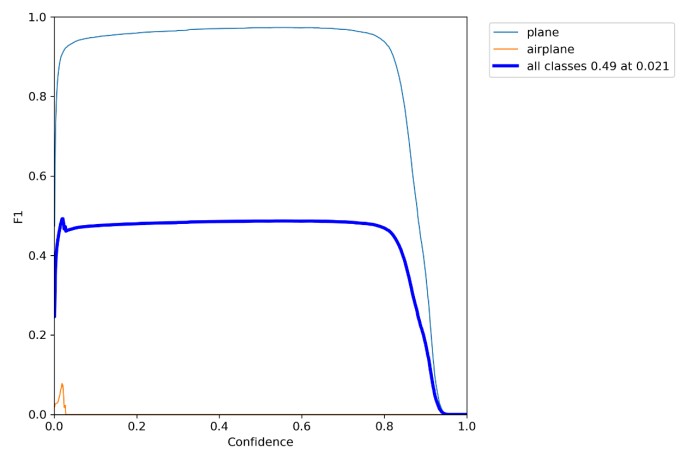
2.F1_Score:数学定义为 F1分数(F1-Score),又称为平衡F分数(Balanced Score),它被定义为正确率和召回率的调和平均数。我们得到的结果为
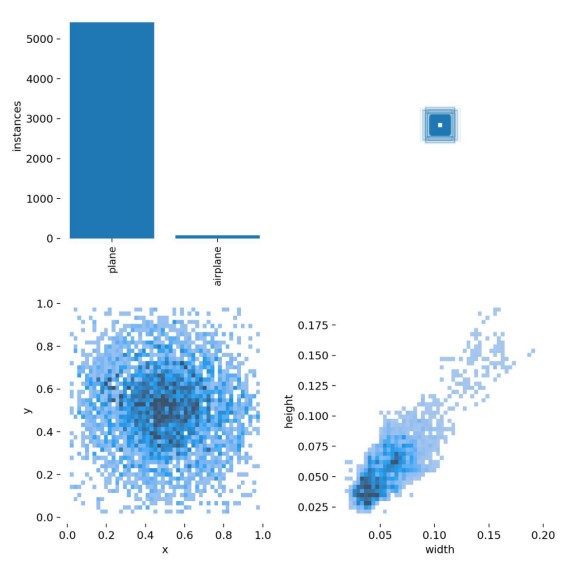
3.labels.jpg
第一个图 classes:每个类别的数据量
第二个图 labels:标签
第三个图 center xy
第四个图 labels 标签的长和宽
由得到的图可知 Plane的数据量远远高于airplane
4.R_curve.png
召回率Recall和置信度confidence之间的关系
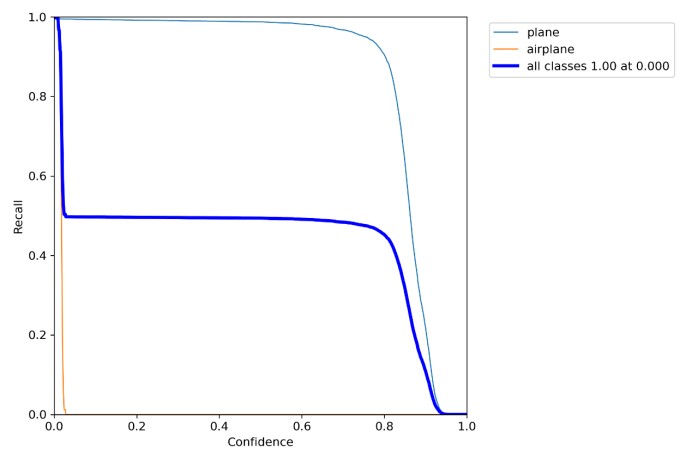
这里可以看出召回率越高,置信度越低,即它们成反比
5.可视化训练结果
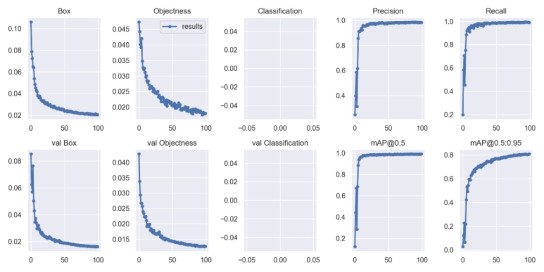
⑴Box:YOLOv5使用GlOU Loss作为bounding box的损失,Box推测为GlOU损失函数均值,越小方框越准,由结果知方框准确性很高
⑵Objectness:推测为目标检测loss均值,越小目标检测越准确,由结果知目标检测准确度很高
⑶Classification:推测为分类loss均值,越小分类越准,由于研究的是单分类问题,故此处没有值
⑷Precision:指模型的精确度,由结果知精确度趋向于1
使用Tensorboard可视化工具得到的结果:
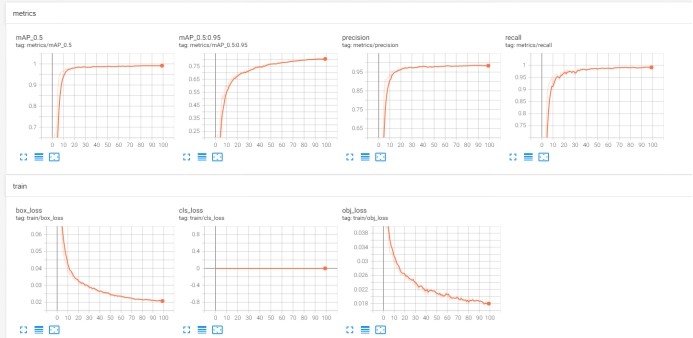
分析:
由可视化结果可以看出此次训练的精确度和召回率都挺高,效果较好,观察mAp可知,训练模型的平均精度也较高。在训练100轮后,box_loss较低,说明检测框比较准确;由于没有分类,所以cls_loss为零;obj_loss在100轮训练之后数值较低,说明目标检测比较准确。
6.测试效果
在训练完成后,利用训练出来的权重进行目标检测,部分检测结果如下:

5 课程心得
通过这次课程的学习,我们小组了解到了模式识别与机器学习在当今发展中的重要作用。图像和模式的识别属于计算机研究的前沿领域,是我们需要去了解的内容,将来也会是我们所需要攻克的难题。图像识别具有十分广泛的用途和巨大的实用价值,在教育,交通,医疗,军事等方面都有重要的作用。
通过这次大作业,我们小组深入了解了YOLOv5模型,通过实践更加深入的了解了课程上所学习的内容和方法。在完成作业的过程中遇到了各种各样的问题和各种各样的bug,通过互相的帮助查找资料,最终完成了这次的作业。通过真实的写代码然后运行,我们才能发现理论和实际的区别,看似只需要安装一个依赖包,但是依赖包的却不一定能顺利安装,安装好后也不一定能顺利运行。只有了解这些区别,我们才能更好的把理论运用在实践中。我们在作业的完成中也借助了网上的资源,合理利用手中现有的资源来帮助我们完成任务也是非常重要的一点,这样就不需要我们从零开始,而是可以踩在巨人的肩膀上继续前行。
我们小组选取了我们感兴趣的YOLOv5模型来对数据集进行检测与识别,虽然过程十分复杂,有时还会调试代码到凌晨,但是在最终完成后的快乐也是巨大的。我们在复习了已有知识的同时还扩展了新的能力,这种实践能力也是一种宝贵的财富。这次的大作业是一次契机,让我们小组能够学习到更多的东西,令人受益匪浅。
6 小组分工
项目需求分析与调研:确立目标与现实意义(杜孟科)
部署代码:形成实际可用项目(王鸣浩)
精度评估:对检测精确度和准确性进行分析(武樊琛)
上传代码与报告:将代码上传到实验平台,word转markdown上传到博客(李宇葳)
课上汇报:撰写文档并汇报(张戟刚)
7 GitLab
- 发表于 2023-04-27 21:43
- 阅读 ( 1973 )
