基于卷积神经网络的齿轮箱数据集分类处理
一、分类问题描述
齿轮箱故障诊断数据集由东南大学收集并公开,已经被广泛用于数字信号方面以及深度学习方面的研究工作。变速箱数据集来自动力传动系统动态模拟器(DDS)。如图1所示。通过旋转研究了两种不同的工况速度系统负载设置为20hz-0v或30hz-2v。不同类型的分类如表1所示。在每个原始mat文件中,有8个排信号:1、电机振动、2、3、4、行星齿轮箱振动三排方向(x, y, z), 5-电机转矩,6,7,8-三个平行齿轮箱的振动方向(x, y和z)。此外,振动数据标记为2来自x方向行星齿轮箱只设计为matlab文件(.mat)来执行分类任务,根据故障类型进行存储。,每个数据文件命名为“机械部件名称_速度_载荷.mat
([‘ball_20_0.mat’,‘comb_20_0.mat’,‘bearing_health_20_0.mat’,
‘inner_20_0.mat’,‘outer_20_0.mat’,‘ball_30_2.mat’,
‘comb_30_2.mat’,‘bearing_health_30_2.mat’,‘inner_30_2.mat’,‘outer_30_2.mat’,'Chipped_20_0.mat','Gear_Health_20_0.mat',
'Miss_20_0.mat','Root_20_0.mat','Surface_20_0.mat','Chipped_30_2.mat','Gear_Health_30_2.mat','Miss_30_2.mat','Root_30_2.mat','Surface_30_2.mat'])

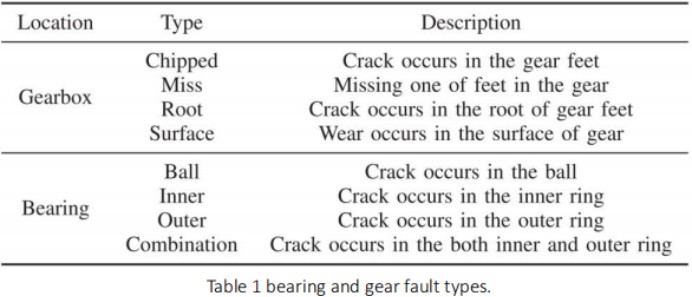
该数据集包括轴承部件的五种不同工作条件齿轮组件:四种故障类型和一种健康状态。因此,故障DDS的分类是一个20类分类任务。
任务描述:
(1) 编写函数进行数据分割,把数据长度为512000的20个样本。对每一类故障建立1000个样本,20类总计20000个样本。
(2) 根据Pythorch数据集的设计规则。设计数据集
(3) 建立深度学习分类模型,至少包括4层神经网络,Epoch不大于100。实现对齿轮箱故障分类。
二. 分类方案
基于课程中的问题分解思路,拟定本问题的解决方案如图 1所示,详细步骤如下:
(1) 构建数据集。通过io.loadmat导入mat数据集。因为数据较少,因此先建立文件标签再按批次提取。可以一次性将所有数据导入。导入后将数据集分为20000份,作为20000个样本数据。并进行归一化。方便后续分类。
(2) 深度学习网络构建。CNN网络进行分类。本文构建网络的思路,先设计一个足够深的CNN网络(防止欠拟合)。然后通过loss曲线和acc曲线结果,对网络的参数及结构进行针对性优化。该过程将在后文进行具体阐述。
(3) 网络与超参数调节。通过loss和acc曲线的结果,分析估计数据的梯度分布情况。调整网络的超参数和网络参数到合适值,得到最优模型
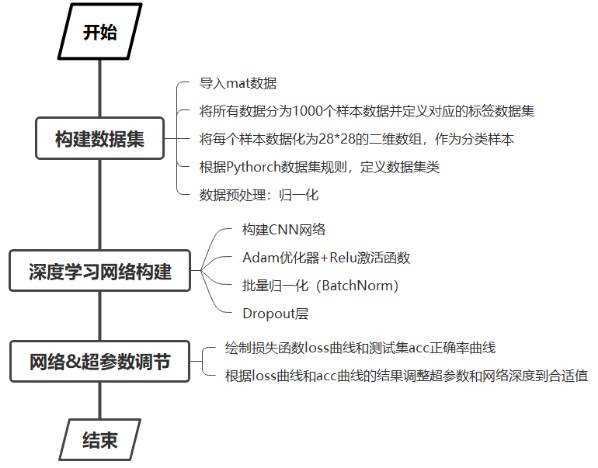
图 1 分类问题的解决方案
三、数据集处理流程
数据集的处理及Pytorch中数据类的构建总共分为以下几个步骤:
(1) 获取所有数据的文件路径。为了保证程序在标签改变、数据量改变的情况下也可以正常运行。首先提取文件路径下的变量路径。以此得到标签和变量数量。其核心实现代码如下
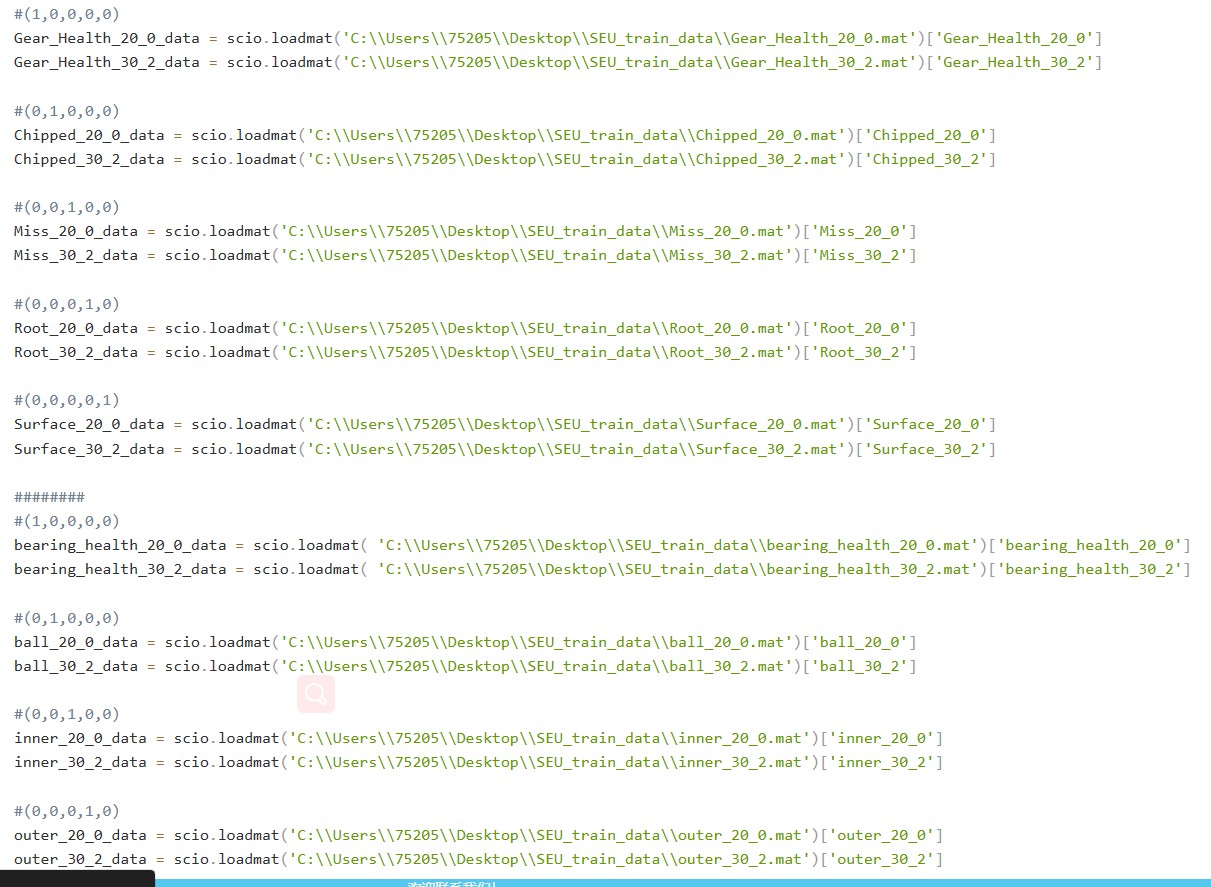
(2) 根据获取的文件路径,分离出标签数据。并导入mat文件数据。并将数据打乱。以方便后续的数据读取。
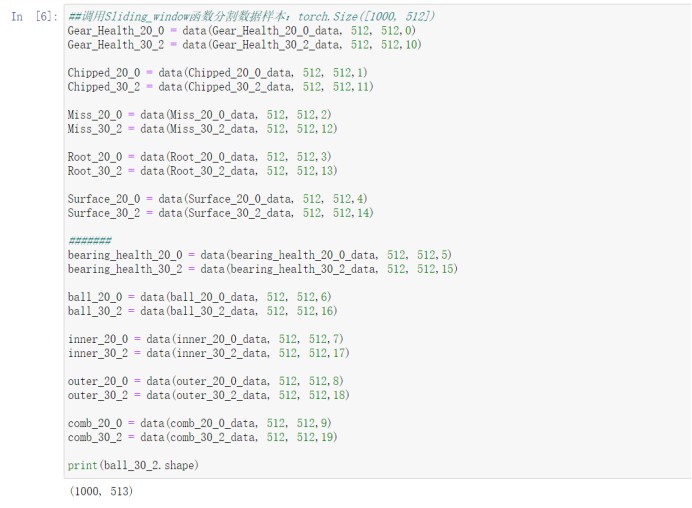
(3) 在对数据进行归一化的同时,编写Sliding_window函数对数据进行滑动分割,同时对每一类数据添加标签。
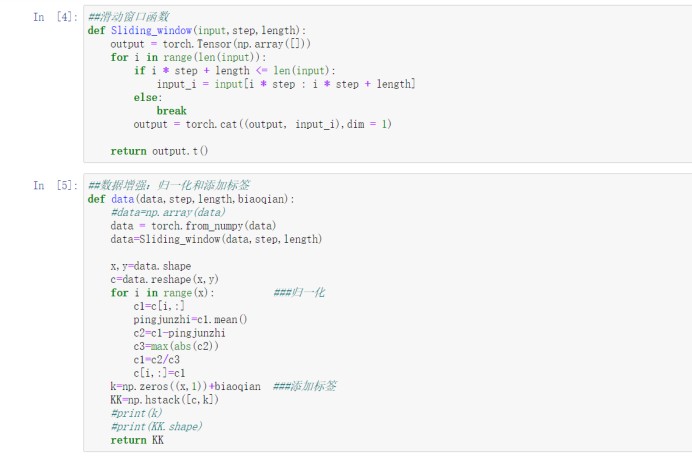
(4) 构建数据类。使用np.vstak函数对数据集进行叠加

(5)对标签进行独热编码

(6) 数据读取。创建类以后,将全部信息读取出来。利用torch中的random_split进行随机切片。训练集和测试集的数据比例为8:2。(这里如果样本的数据总量变了,需要重新设置rand_split中的参数)

四、深度模型结构描述
4.1 网络构建代码解释
图 2为网络构建的代码,其中变量par中的即为网络的参数。
图 2 深度网络的设计代码
4.2 网络结构分析
4.2.1 网络结构概述
最后的网络结构如下面的参数集所示。本文所用网络共包括了8层卷积层,2层全连接层,8层BN层,1层Dropout层。激活函数为ReLU。
def deep_model(feature_dim,label_dim):
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
print("create model. feature_dim ={}, label_dim ={}".format(feature_dim, label_dim))
model.add(Dense(500, activation='relu', input_dim=feature_dim))
model.add(Dense(100, activation='relu'))
model.add(Dense(label_dim, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
此外,优化器选择Adam算法,损失函数为交叉熵,相关超参数设如下:

4.2.2 网络设计要点
Ø 网络深度选择:从上面的网络结构可以看出,对于一个20000*512的分类样本数据而言。本报告设计的网络结构层度较深。其主要原因包括:
1. 数据集足够的大,计算量大。
2. 选择Adam优化算法,SGD算法表现较差
3. 损失函数选择交叉熵,CrossEntropyLoss算法准确率极低
4. 最后一层输出层选择sigmod函数,为配合损失函数交叉熵函数使用。
同时选用softmax函数训练结果准确率极低
注:以上设计要点均在Examination_paper_Part2.1.ipynb文件中体现,Examination_paper_Part2.2.ipynb文件中则使用了相对的表现差的算法与函数
五、分类精度展示

如图所示,在使用了Adam优化算法、二元交叉熵算法、relu+relu+sigmod函数的Examination_paper_Part2.1.ipynb文件中。epoch在10次以内即可收敛,精确度可达86.9%,该模型实现了较高的精确度
六、结论
本报告分析了SEU_train_data数据集的结构和类别,在Pytorch软件框架下,依据分类要求,设计了4层分类网络,精度已到达87%。同时分析了模型训练过程中存在的训练精度和测试精度的变化规律,针对其中的不少问题,从课程中学习的理论进行了分析,提出了相应的解决方案,同时,提出的深度模型在样本充足和较少情况下均到达了较好的分类精度,表明模型具有较好的泛化性能。通过本课程的学习,收获了较多人工智能知识和Python编程技能,在后面的大创实验中,将利用本课程的知识,解决大创中的数据处理问题,实现学以致用。
七、小组分工
找数据集并处理、最终汇报(司卜元)
制作汇报ppt、最终文档并上传博客(崔兆玺)
构建训练模型,优化网络结构、参数(屈程洋)
八、gitlab
- 发表于 2023-04-30 20:29
- 阅读 ( 4583 )
