深度学习主流框架的模型保存与加载
1. TensorFlow
(1)两种模型后缀——
.ckpt/.pb
① ckpt
一般保存结构 + 权重(虽然也可以单独保存权重)。
A. 保存模型
# 定义saver
saver = tf.train.Saver(tf.global_variables())
# 调用train.Saver的save方法
saver.save(sess, ckpt_path, global_step = epoch)
保存后的文件如下:
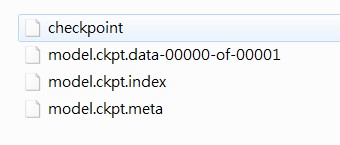
l checkpoint:检查点文件,文件保存了一个目录下所有模型文件列表。
l model.ckpt.data:二进制文件,保存了TensorFlow程序中每一个变量的取值,包括所有weights,biases,gradient and all the other variables。
l model.ckpt.index:保存了TensorFlow程序中变量的索引。
l model.ckpt.meta:保存了TensorFlow计算图的结构,包括variables operations,collections等等。(该文件可以被 tf.train.import_meta_graph 加载到当前默认的图来使用)。
B. 读取模型
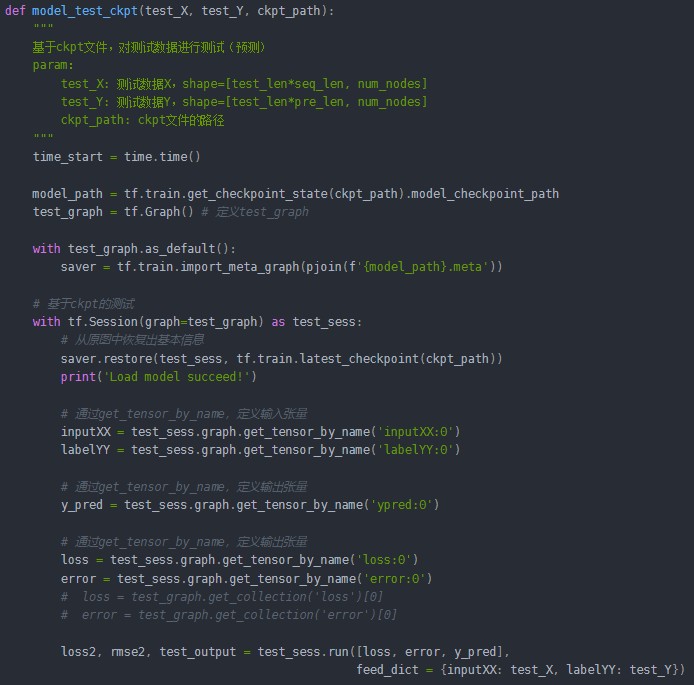
在上述测试代码中,首先定义test_graph,再通过get_tensor_by_name获取训练图中已经定义好的节点。如果不希望重复定义图上的运算,也可以直接加载已经持久化的图,以下代码给出一个简单实现样例:
graph = tf.get_default_graph().as_graph_def() # 获得默认的图
y_pred = test_sess.graph.get_tensor_by_name('ypred:0')) # 获取图中的ypred
在上述过程中,我们将TensorFlow模型保存为 ckpt 格式的模型文件,但是这种保存方式有几个缺点:
l 这种模型文件是依赖 TensorFlow 的,只能在其框架下使用。
l 在恢复模型之前还需要再定义一遍网络结构,然后才能把变量的值恢复到网络中。
l 保存模型文件的时候会产生多个文件,它将变量的取值和计算图结构分成了不同的文件存储。
l 使用 tf.train.Saver 默认保存和加载了TensorFlow计算图上定义的所有变量,但是有时可能只需要保存或者加载部分变量。(比如: (1)在测试或者离线预测时,只需要知道如何从神经网络的输出层经过前向传播计算得到输出层即可,而不需要类似于变量初始化,模型保存等辅助接点的信息。(2) 再比如,可能有一个之前训练好的五层神经网络模型,现在想尝试一个六层神经网络,那么可以将前面五层神经网络中的参数直接加载到新的模型,而仅仅将最后一层神经网络重新训练。)
② pb
一般保存结构 + 权重。
谷歌推荐的保存模型的方式是保存模型为 PB 文件,它具有语言独立性,可独立运行,封闭的序列化格式,任何语言都可以解析它,它允许其他语言和深度学习框架读取、继续训练和迁移 TensorFlow 的模型。另外的好处是保存为 PB 文件时候,模型的变量都会变成固定的,导致模型的大小会大大减小,适合在手机端运行。
那么模型保存为pb文件的形式也可以分为两种:直接保存为pb文件、从ckpt转pb文件(略)。
A. 保存模型
# convert_variables_to_constants 将图中的变量转化为常量,固化模型结构
output_graph = graph_util.convert_variables_to_constants(
sess=sess,
input_graph_def=sess.graph_def,
output_node_names=['ypred']
)
# 写入序列化的pb文件
with tf.gfile.GFile(pb_path, 'wb') as f:
f.write(output_graph.SerializeToString())
B. 读取模型
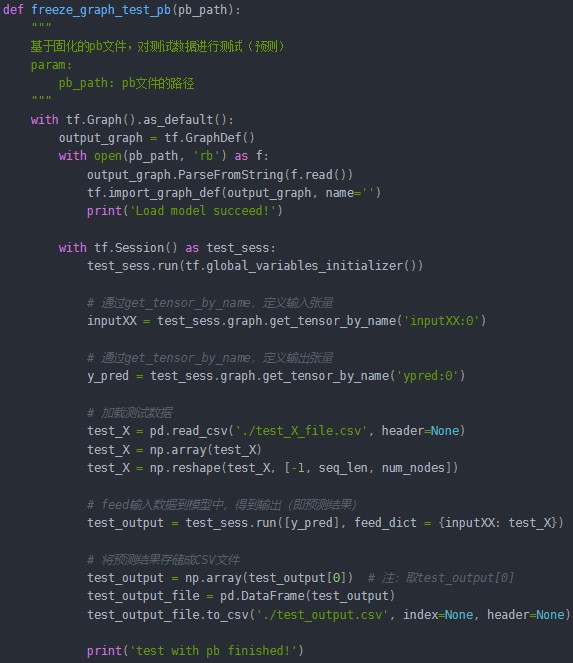
l 与ckpt预测不同的是,pb文件已经固化了网络模型结构。因此,即使不知道原训练模型(train)的源码,我们也可以恢复网络图,并进行预测。恢复模型非常简单,只需要从读取的序列化数据中导入网络结构即可:
tf.import_graph_def(output_graph, name="")
l 但是必须知道原网络模型的输入和输出的节点名称(当然了,传递数据时,是通过输入输出的张量来完成的)。由于LSTM模型的输入有1个节点,因此这里需要定义输入的张量名称,它对应的网络结构的输入张量:
inputXX = test_sess.graph.get_tensor_by_name('inputXX:0')
l 定义输出张量:
y_pred = test_sess.graph.get_tensor_by_name('ypred:0')
l 预测时,需要 feed输入数据:
test_output = test_sess.run([y_pred], feed_dict = {inputXX: test_X})
参考:Tensorflow模型持久化 (ckpt & pb)_酒酿小圆子~的博客-CSDN博客_ckpt pb
tensorflow三种加载模型的方法和三种模型保存文件(.ckpt,.pb, SavedModel) - 彼岸的客人 - 博客园 (cnblogs.com)
2. Pytorch
(1)两种保存模型的方式
①权重 + 结构
# 创建你的模型实例对象: model
model = net()
A. 保存模型
torch.save(model, 'model_name.pth')
B. 读取模型
model = torch.load('model_name.pth')
②权重
A. 保存模型
torch.save({'model': model.state_dict()}, 'model_name.pth')
B. 读取模型
model = net()
state_dict = torch.load('model_name.pth')
model.load_state_dict(state_dict['model'])
我们可以看到第一种方法可以直接保存模型,加载模型的时候直接把读取的模型给一个参数就行。而第二种方法则只是保存参数,在读取模型参数前要先定义一个模型(模型必须与原模型相同的构造),然后对这个模型导入参数。虽然麻烦,但是可以同时保存多个模型的参数,而第一种方法则不能,而且第一种方法有时不能保证模型的相同性(你读取的模型并不是你想要的)。
参考:pytorch保存模型的两种方式_SCU-JJkinging的博客-CSDN博客_pytorch保存模型
(2)三种模型后缀 —— .pt/.pth/.pkl
它们并不存在格式上的区别,只是后缀名不同而已。在torch.save()函数保存模型文件的时候,有些人喜欢用.pt后缀,有些人喜欢用.pth或.pkl,用相同的torch.save()语句保存出来的模型文件没有什么不同。
在PyTorch官方的文档里,有用.pt的,也有用.pth的。据某些文章的说法,一般惯例是使用.pth,但是官方文档里貌似.pt居多,而且官方也不是很在意固定地用某一种。
3. Keras
模型后缀为h5。
(1)三种保存模型的方式
① 结构 + 权重 + 优化器状态
from keras.models import load_model
A. 保存模型
model.save('my_model.h5') # 创建 HDF5 文件 'my_model.h5'
del model # 删除现有模型
# 返回一个编译好的模型
# 与之前那个相同
B. 读取模型
model = load_model('my_model.h5')
② 结构
A. 保存模型
# 保存为 JSON
json_string = model.to_json()
# 保存为 YAML
yaml_string = model.to_yaml()
B. 读取模型
# 从 JSON 重建模型:
from keras.models import model_from_json
model = model_from_json(json_string)
# 从 YAML 重建模型:
from keras.models import model_from_yaml
model = model_from_yaml(yaml_string)
③ 权重
A. 保存模型
model.save_weights('my_model_weights.h5')
B. 读取模型
model.load_weights('my_model_weights.h5')
model.load_weights('my_model_weights.h5', by_name=True) # 将权重加载到不同的结构(有一些共同层)的模型中,例如微调或迁移学习,则可以按层的名字来加载权重
- 发表于 2022-07-23 18:10
- 阅读 ( 2559 )
- 分类:ROS及基础开发
