论文分享——零样本知识蒸馏用于联邦类增量学习
论文链接:https://arxiv.org/abs/2303.06937
发表会议:ICCV 2023
TARGET: Federated Class-Continual Learning via Exemplar-Free Distillation
1.摘要
现有的很多联邦学习方法都是应用在静态场景中的,但是实际的应用场景通常是动态的。本文关注在联邦学习的框架下动态添加新类——联邦类增量学习(FCIL)。首先证明了non-iid的数据分布会加剧FL中的灾难性遗忘,然后提出了一种新的方法——TARGET(federatTed clAss-continual leaRninG via Exemplar-free disTillation),通过通过零样本知识蒸馏进行的联邦类增量学习,不需要存储额外的数据集,可以应用于隐私敏感的场景,在CIFAR-100、TinyImageNet数据集上证明了方法的有效性。
2.引言
联邦学习是一种保护隐私的分布式学习框架,它允许每个客户端使用自己的本地数据训练一个由中央服务器分发的全局模型,然后服务器聚合所有参与训练的设备的模型参数以获得一个新的全局模型,由于各个客户端之间不需要交换模型参数,解决了用户隐私、数据孤岛的问题。
传统的FL方法假设数据类和数据域是静态的,但是在现实中,随着时间的推移,可能会出现新的数据类。对于不断出现数据类的问题,一个直观的解决方案是从头开始训练模型,但这是不切实际的(大量的额外计算成本);另一种方法是从旧模型中迁移学习,但往往会出现灾难性遗忘现象,在旧类数据上的性能直线下降。为了解决这个问题,引入联邦类增量学习,旨在缓解在FL框架下,不断学习新类数据的同时保持对旧类数据的分类性能。
在一些隐私敏感的场景下(例如医疗场景、金融场景等),不允许本地客户端存储私有数据,一些在类增量学习中性能较好的基于数据回放的方法可能不再适用。与此同时,FL客户机之间的数据分布不平衡——即non-iid现象加剧了灾难性遗忘问题。
本文贡献:
- 首次证明了非独立同分布(non-IID)数据加剧了FL中的灾难性遗忘问题
- 提出了一种新的方法TARGET(federatTed clAss-continual leaRninG via Exemplar-free disTillation),通过零样本蒸馏进行的联邦类持续学习,不需要存储额外的数据集,可以应用于隐私敏感的场景
- 在CIFAR-100、TinyImageNet数据集上证明了方法的有效性
3.研究方法
3.1问题定义
- 参与方由一个服务器和多个客户端组成,客户端-服务器、客户端-客户端之间不共享数据
- n个任务序列{C_1,C_2,C_3⋯},类别之间不重叠
- 每个客户端只能在任务k的训练期间访问任务k的本地数据(C_k的子集,non-IID)
3.2优化目标
最小化全局模型在新任务和旧任务的总体分类误差:
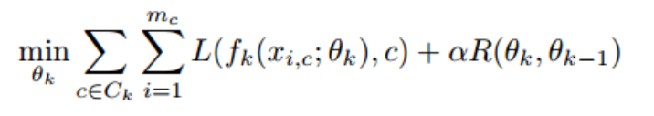
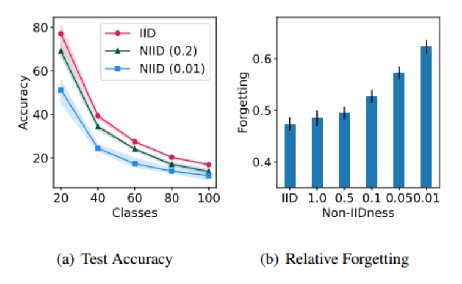
3.3异构数据加剧灾难性遗忘
随着新任务的到来,模型的准确性会下降,较高的non-IID设置,性能更差,加剧了遗程度。结果表明,FCIL在极端的non-iid环境下面临重大挑战。
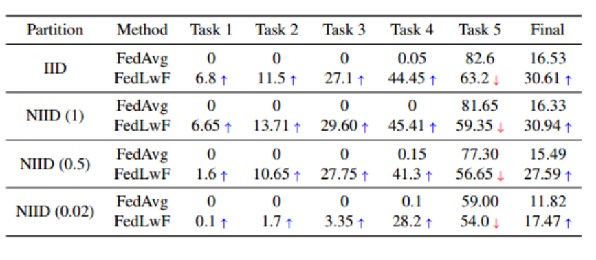
3.4利用全局信息可以减轻遗忘
3.4.1从全局模型中提取旧知识
将经典的持续学习方法LwF应用在FL中,构造FedLwF,和FedAvg相比,利用旧的全局模型进行知识蒸馏,将全局模型的知识传递给当前任务,可以改善在连续任务上的性能,并减轻灾难性遗忘问题。
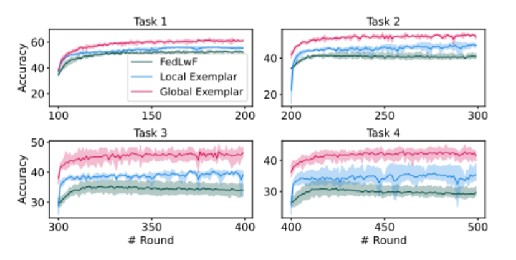
3.4.2从全局样本中提取旧知识
首先解释一下什么是全局样本,相应的也存在局部样本。
- 全局样本:假设服务器汇总所有客户端的一部分旧类数据,再分发下去。但是这在FL中是不被允许的,这里是做的一个假设。
- 局部样本:每个客户端从旧的本地数据中保留部分样本。
实验结果表明,回放全局样本可以显著的改善模型的性能。
Question:如何获得全局样本?????
3.5方法设计
上一小节讲到利用全局样本通过全局模型进行知识蒸馏可以显著提升模型性能,但是由于数据隐私等原因,我们是无法拿到真实的全局样本的。既然不能拿到真实的全局数据,是否可以考虑合成数据呢?这篇文章的核心思想就是提出了一种使用数据生成器的方法,在不涉及用户真实数据的情况下利用全局信息生成合成数据提取旧任务知识。
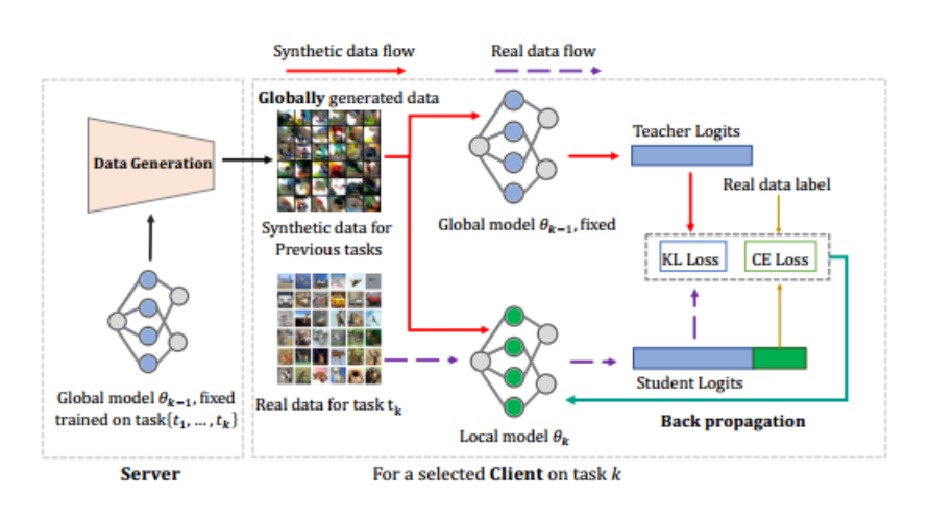
- server side:模型参数聚合、训练数据生成器合成数据
- client side:使用合成数据和新任务数据共同训练本地模型,通过知识蒸馏提取旧全局模型的知识
3.5.1server side:Synthesizing Data for Old Tasks
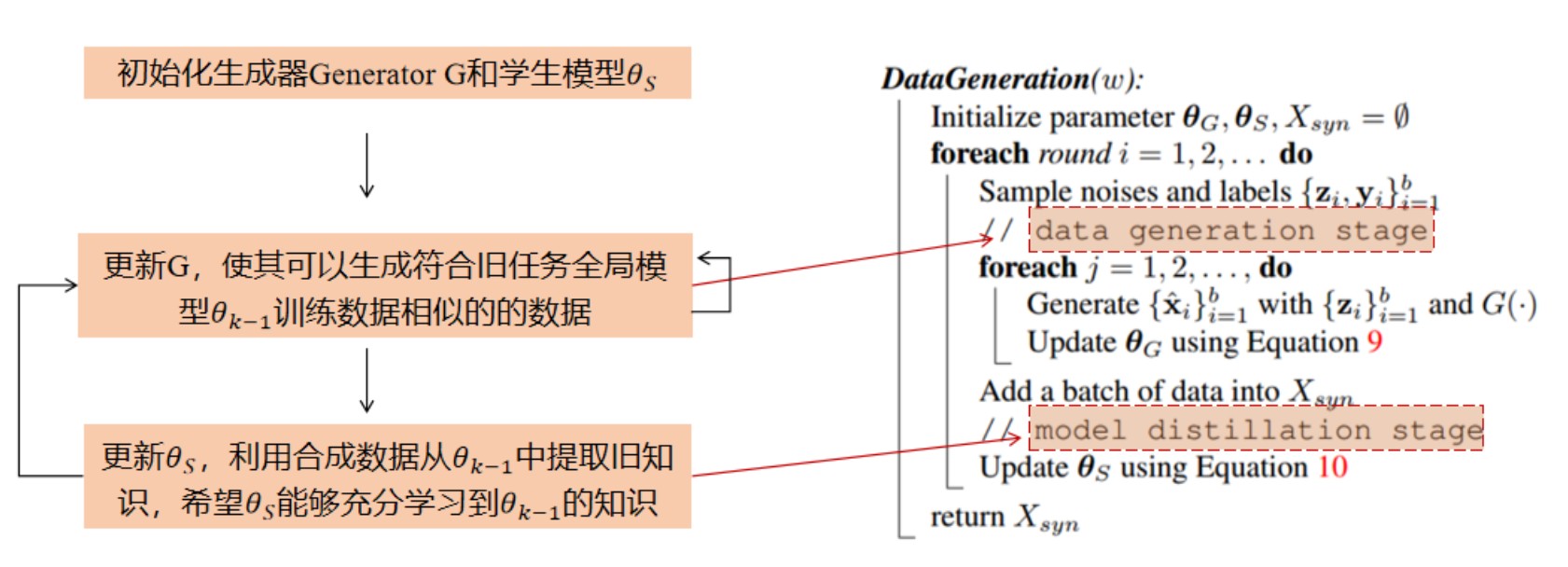
3.5.1.1Data Generation Stage
通过随机噪声 z 和 Generator G 生成合成数据 x ̂=G(z),高质量的合成数据可以使客户端的本地模型更充分地学习到旧的全局模型的旧知识,合成数据的质量如何衡量?从相似性、可迁移性、稳定性三个方面衡量。
相似性:使θ_k−1在合成数据 x ̂ 上的预测接近随机生成的标签 y ̂ ,确保合成数据与训练数据的相似性。
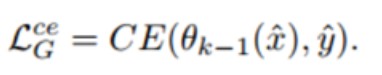
可迁移性:仅仅使用上一步的损失函数可能会导致生成器过度拟合到远离模型决策边界的合成数据,无法提供更好的性能。增强知识蒸馏的意义,引入边界损失,生成更复杂的数据。
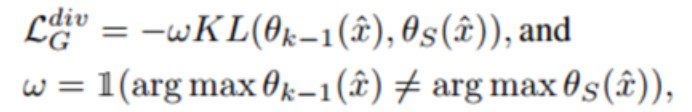
稳定性:通过BN损失确保合成数据的统计特性(均值和方差)与批量归一化层的期望值一致,从而提高生成器的稳定性。
3.5.1.2Model Distillation Stage
学生模型可以帮助训练生成器,生成更复杂、多样的样本,一个好的学生模型帮助训练一个更好的生成器
对生成器训练几轮之后,更新学生模型,训练损失函数如下:
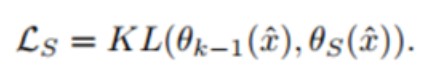
得到一个性能更好的学生模型,进一步更新生成器
3.5.2Client side:Update with Global Information
使用合成数据和新任务数据共同训练本地模型,通过知识蒸馏提取旧全局模型的知识
- 发表于 2024-01-23 00:09
- 阅读 ( 4038 )
- 分类:群智能体知识迁移
