论文分享——新思路:向前兼容的小样本类增量学习
论文链接:https://arxiv.org/abs/2203.06953
发表会议:CVPR 2022
Forward Compatible Few-Shot Class-Incremental Learning
1 摘要
在小样本类增量学习中,考虑一种新的研究思路,向前兼容的方法,前向兼容性要求未来的新类能够基于当前阶段的数据轻松地合并到当前模型中,这篇文章提出一种方法 ForwArd Compatible Training (FACT) ,通过为未来的新类保留嵌入空间来实现这一点。
2 引言
接着为大家带来一篇小样本类增量学习文章的分享,想了解原型学习、类增量学习以及小样本学习的都可以看看~~~小样本类增量学习相信大家基本都了解过,如何像人类一样,只通过很少的样本就能掌握某一类知识。举例来说,对于幼儿园的小朋友来说,他们接受新事物的能力也是很强的。如何让他们辨别一个新的动物,例如河马,通过一两张照片小朋友们就已经可以具备这个能力。但是,对于神经网络来说,可能需要大量的样本才能识别一个新类别。因此,小样本类增量学习除了需要解决传统类增量学习面临的灾难性遗忘问题以外,还需解决由于较少的样本量导致的过拟合问题,因此更具有挑战性。这些之前已经说过很多次了,下面进入正题。/////////开始进入正题//////////那这篇文章又有什么不一样呢?当前的很多CIL方法通过维护旧类的可辨别性来寻求后向兼容性,集中于后向兼容性将克服遗忘的负担转移到后面的模型。然而,如果前一个模型工作不好的话,后一个模型也随之退化。以软件开发为例。如果早期版本设计得很差,那么后期版本就需要努力添加补丁以保持向后兼容性。相比之下,更好的解决方案是在早期版本中考虑未来的扩展,并提前保留接口。因此,另一种兼容性,即前向兼容性更适合FSCIL,它为将来可能的更新做好了准备。
因此,本文主要关注的是前向兼容性,期待训练的模型是可生长和可预见的。一方面,可增长意味着模型能够意识到未来将要出现的类,并为它们的嵌入空间腾出空间。因此,模型在更新时不需要压缩以前类的空间来为新类腾出空间。另一方面,该模型应预测未来,并制定方法,以尽量减少未来事件的冲击和压力的影响。得益于前向兼容性,旧类的嵌入空间将更加紧凑,新类可以很容易地匹配到保留的空间,如下图所示。
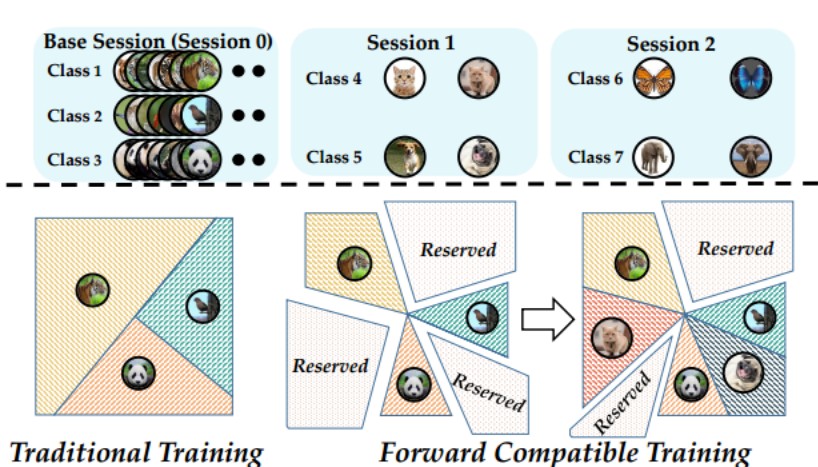 本文贡献:
本文贡献:
(1)为了使模型具有可生长性,在嵌入空间中预先分配多个虚拟原型,将它们假定为预留空间。
(2)通过来自不同的类别进行实例混合,生成虚拟实例,使模型具有可预见性。
(3)在cifar100、CUB200、miniImageNet、ImageNet100、InageNet1000数据集上验证了FACT方法的优越性。
3 问题定义
问题定义略过,大家可以参考之前的小样本类增量学习开山之作这篇博客的问题定义。
4 研究方法
4.1 使用虚拟原型进行预训练
4.1.1 虚拟原型的分配
在这篇文章中应用了原型学习,为每个类别训练一个原型,分类时根据输入样本与原型的相似性进行判断,也就是说用类原型替换分类器权重。大家可以看看下面这个公式,第一项匹配输出和真实的标签。第二项,使用Mask(·)函数将ground-truth logit屏蔽掉,再将剩余的部分和伪标签匹配。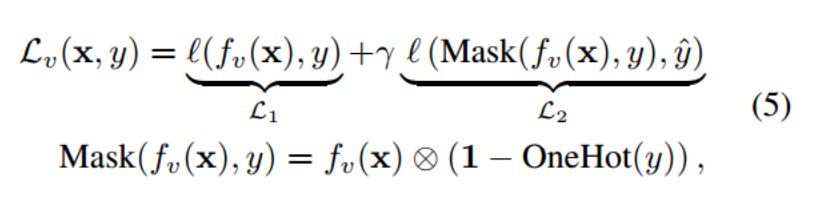
如下图中的左边所示,第一项强制实例离ground-truth簇最近,第二项将其和最近的虚拟簇匹配。通过优化上述公式,将所有非目标类原型从保留的虚拟原型中推开,将决策边界向同一方向推开。这样,其他类的嵌入将更加紧凑,并且保留了虚拟类的嵌入空间。因此,模型变得可增长,并增强了前向兼容性。
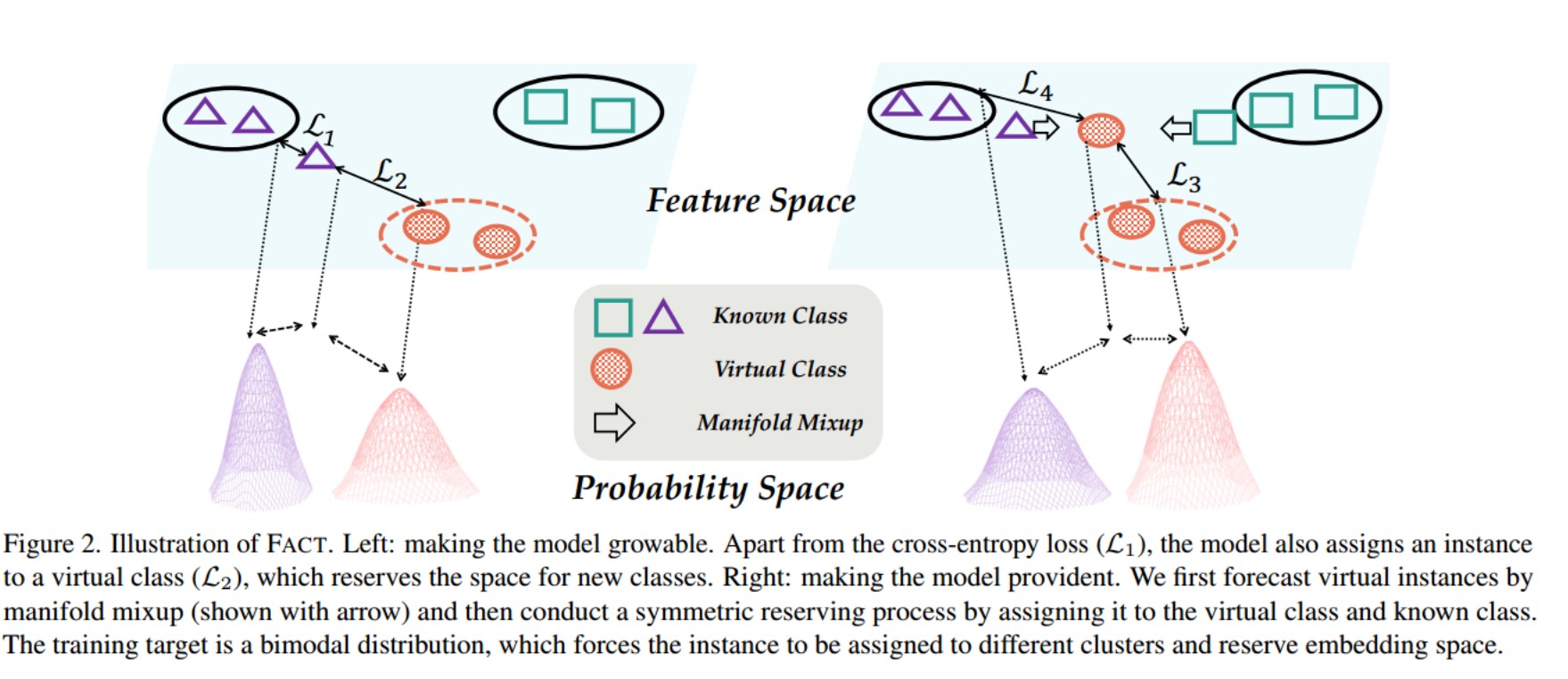
4.1.2 预测虚拟实例
为了使模型具有预见性,为模型配备“未来证明”的能力——如果它在预训练阶段看到了新的类别,那么保留的空间将更适合即将到来的新类。为此,文章尝试通过实例混合来生成新的类,并为这些生成的实例保留嵌入空间。在中间层将嵌入解耦为两个部分:φ(x) = g(h(x))。对于一个mini batch的样本,采样一对来自不同类别的样本,(xi;xj),将这对样本的嵌入融合成一个虚拟样本:
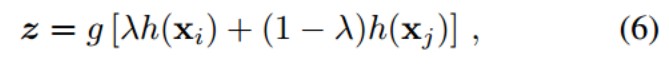
然后为虚拟样本z建立一个损失函数,以保留嵌入空间:
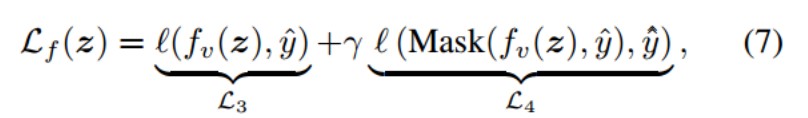 y/\和公式(5)一样表示虚拟类别的伪标签,y/\/\是当前已知类别的伪标签。生成虚拟类可以预测传入的新类的可能分布,如上图的右侧所示。第一项将混合实例z推向虚拟原型并远离其他类,为虚拟类保留空间。此外,第二项将混合实例推向最近的已知类,在已知类和虚类之间进行权衡,以防止已知类被过度压缩。因此,通过模拟未来的实例,模型变得有预见性,并增强了前向兼容性。
y/\和公式(5)一样表示虚拟类别的伪标签,y/\/\是当前已知类别的伪标签。生成虚拟类可以预测传入的新类的可能分布,如上图的右侧所示。第一项将混合实例z推向虚拟原型并远离其他类,为虚拟类保留空间。此外,第二项将混合实例推向最近的已知类,在已知类和虚类之间进行权衡,以防止已知类被过度压缩。因此,通过模拟未来的实例,模型变得有预见性,并增强了前向兼容性。
以上就是主要的思想。
5 实验结果
大家可以看看实验结果,比目前的SOTA方法-CEC(持续演化的分类器,之后有机会也可以向大家介绍一下这个方法,简单来说是使用了一个图神经网络来训练分类器)的效果要好一点。
- 发表于 2024-02-23 15:07
- 阅读 ( 2906 )
