论文分享——Is a Modular Architecture Enough?
Is a Modular Architecture Enough?
1 Introduction
深度学习研究者从神经科学和认知科学中汲取灵感,从隐藏单元、输入方式,到网络连接、网络架构的设计等,许多突破性研究都基于模仿大脑运行策略。认知神经科学研究表明,大脑皮层以模块化的方式表示知识,不同模块之间进行通信,使用注意力机制进行内容选择。受此启发,近年来的机器学习系统逐渐显露稀疏性和模块化架构的优势。模块化架构不仅具有良好的泛化性能,而且还能带来更好的分布外(OoD) 泛化、可扩展性、学习速度和可解释性。
此类系统成功的一个关键是,利用高级变量之间稀疏的依赖关系,将知识分解为尽可能独立的可重组片段,使学习更有效率。用于真实世界设置的数据生成系统被认为由稀疏交互部分组成,赋予模型类似的归纳偏置将是有帮助的。然而,由于这些真实世界的数据分布是复杂和未知的,该领域一直缺乏对这些系统进行严格的定量评估。尽管最近许多工作基于模块化架构取得了不错的成果,大量的tricks和提出的架构修改使得解析真实的、可用的架构原则变得具有挑战性。
Mixture-of-Experts (MoE) 是一种模块化架构,它结合了专家模型(experts)和一个 gating network。在 MoE 中,专家模型负责处理特定类型的输入或任务,而 gating network 则用来确定在特定情况下应该使用哪个专家模型。同样,我们不清楚基于专家组合(MoE)的模块化系统所获得的性能提升的原因究竟是什么?是由于良好的专业化,还是由于其他潜在的混杂因素(如易于优化)。为此,本研究开发了一系列基准和指标来评估、量化和分析模块化架构的常见组成部分,旨在探索模块化网络的效能。这不仅有助于识别当前方法的成功之处,还有助于识别这些方法何时以及如何失败的。
2 Notion
Research Purpose
本文通过执行一组共同的任务研究和分析模块化系统,这些任务由基于规则的数据生成系统制定。以下介绍关键组成部分的定义,包括 (1) rules 以及它们如何形成任务,(2) modules 以及它们如何采用不同的模型架构,(3) specialization 以及如何评估模型。
Terminology
Rules.
是一个数据生成分布,基于数学公式、领域知识等规范来定义,用于生成符合特定要求的数据
Tasks.
由一组规则定义,不同规则的组合意味着不同的任务,模型在多个任务上训练以消除对特定任务的bias。
Modules.
模块化系统由一组神经网络模块组成,每个模块都可以对整体输出做出贡献。
Model Architectures.
为模块化系统的每个模块考虑不同模型架构,包括多层感知器 (MLP) 、多头注意力 (MHA) 和循环神经网络 (RNN) 三种。Perfect Specialization.
在基于规则的数据上训练模块化系统时,我们希望模块基于规则进行专业化(即,期望不同的模块专门针对不同的规则)。因此,一个重要的需要来量化是什么构成了系统对数据的完美专业化。为了便于量化,本文设置所有的数据规则都是等概率的,模型的模块与数据规则数目相同。Methods
Data Generating Process
本文探索了基于三种不同模型体系结构的数据生成过程:MLP、MHA和RNN。此外,每个任务都有两个版本:回归和分类。这些设置是为了探索不同的损失类型可能引起的潜在差异。 在所有设置中,数据来自MoE分布 (MoE中 gating network 输出的概率分布),它描述了每个专家模型被选择的概率。当在基于规则的合成数据集对模块化架构进行端到端训练时,我们希望专家们能基于规则学习到完美的专业化,并验证这种完美的专业化在不同设置下是否有帮助。
在所有设置中,数据来自MoE分布 (MoE中 gating network 输出的概率分布),它描述了每个专家模型被选择的概率。当在基于规则的合成数据集对模块化架构进行端到端训练时,我们希望专家们能基于规则学习到完美的专业化,并验证这种完美的专业化在不同设置下是否有帮助。Models
以往一些工作宣称端到端训练的模块化系统优于单体系统,尤其是在分布式环境中。但是对于这些模块化系统的好处,以及它们是否真的根据数据生成分布进行了专业化还没有详细和深度的分析。本文研究四类具有不同程度专业化的模型:
 Monolithic。一个典型神经网络。系统中不包含稀疏性或模块化的归纳偏置,完全依靠反向传播来学习解决任务所需的函数。Modular。由很多模块组成,每个模块都是给定架构类型的神经网络。存在显式的内置模块化归纳偏差,但它仍然取决于系统范围的反向传播来确定正确的专门化。Modular-op。激活概率 p 仅为规则上下文 c 的函数,在计算不同模块的专门化时不会受到 x 的干扰。GT-Modular。完美专业化的模块化系统,激活概率直接由 c 指定,可以根据不同的数据规则稀疏而完美地选择不同的模块。
Monolithic。一个典型神经网络。系统中不包含稀疏性或模块化的归纳偏置,完全依靠反向传播来学习解决任务所需的函数。Modular。由很多模块组成,每个模块都是给定架构类型的神经网络。存在显式的内置模块化归纳偏差,但它仍然取决于系统范围的反向传播来确定正确的专门化。Modular-op。激活概率 p 仅为规则上下文 c 的函数,在计算不同模块的专门化时不会受到 x 的干扰。GT-Modular。完美专业化的模块化系统,激活概率直接由 c 指定,可以根据不同的数据规则稀疏而完美地选择不同的模块。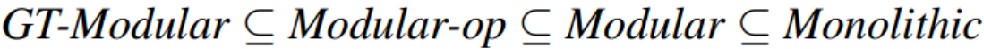
Metrics
Performance
对于分类设置报告错误率,而对于回归设置报告loss。考虑分布内和分布外两种设置。In-Distribution:通过查看不同模型的最终性能和收敛速度来评估Out-of-Distribution:考虑(a)增加方差改变x的分布,(b)不同的序列长度(在MHA和RNN中)。Collapse
崩溃是指模块未被充分利用的程度。
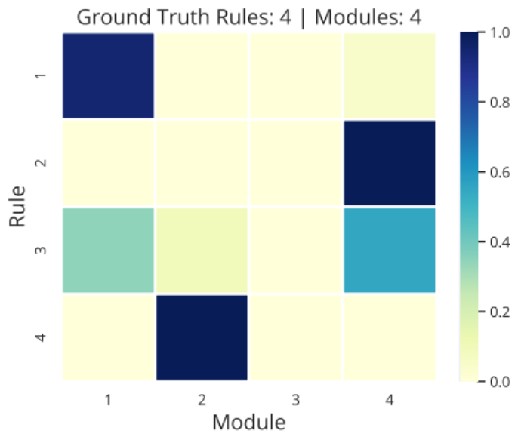
Collapse-Avg(↓):旨在捕获系统所有模块的未充分利用的程度
 Collapse-Worst(↓):旨在捕获系统中最少使用的模块的崩溃程度
Collapse-Worst(↓):旨在捕获系统中最少使用的模块的崩溃程度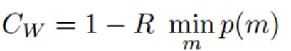
Specialization
旨在捕获模块对规则的专业化程度。最好的专业化——不同的模块坚持不同的规则;最差的专业化——每个模块对于所有规则的贡献度相同。
Alignment(↓):显示当前系统与完美专业化系统的接近程度 Inverse Mutual Information(↓):越低表示每个模块更倾向于对应于一个独特的规则
Inverse Mutual Information(↓):越低表示每个模块更倾向于对应于一个独特的规则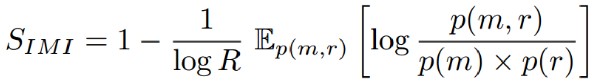 Adaptation(↓):可以理解为模块对规则分布(p(·))变化的适应程度(q(·))
Adaptation(↓):可以理解为模块对规则分布(p(·))变化的适应程度(q(·))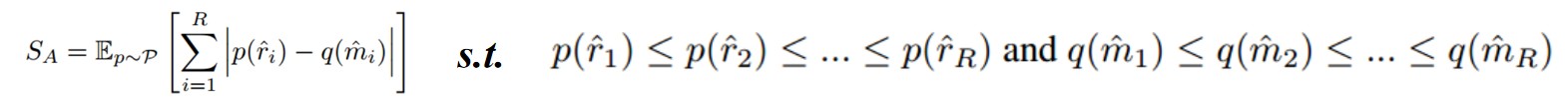
Experiment
为了正确分析模块化系统的好处、端到端训练系统获得的专业化程度、规则数量的影响和模型容量的影响,本文基于以下设置的不同组合进行实验:- 四个模块化级别:Monolithic, Modular, Modular-op, GT-Modular
- 五个不同数量的规则:2, 4, 8, 16, 32
- 五种不同的模型容量(即参数数量)
- 两种不同的训练设置(分类和回归)
- 三种模型架构:MLP, MHA, RNN
- 五个不同的任务(规则的随机组合)
- 五个随机种子
综上,本文共训练了约20,000个模型,每个模型需要在V100 GPU上训练数个小时,消除了可能由特定任务或模型等带来的不必要偏差。
Results
Performance
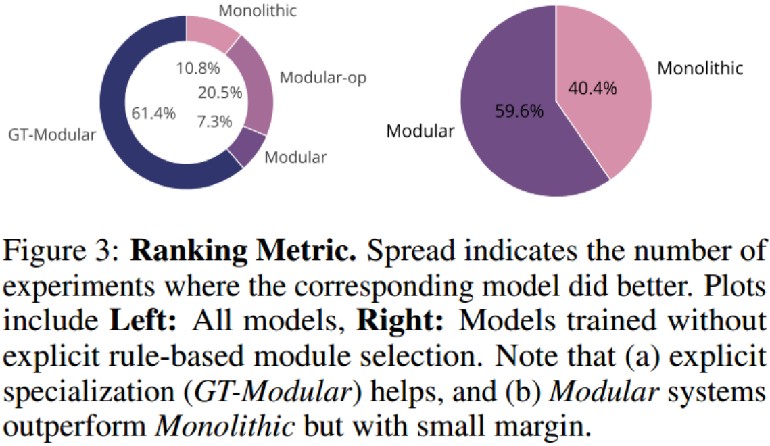 GT模块化在大多数情况下最优
GT模块化在大多数情况下最优- 标准端到端模块化优于非模块化,但差距不大
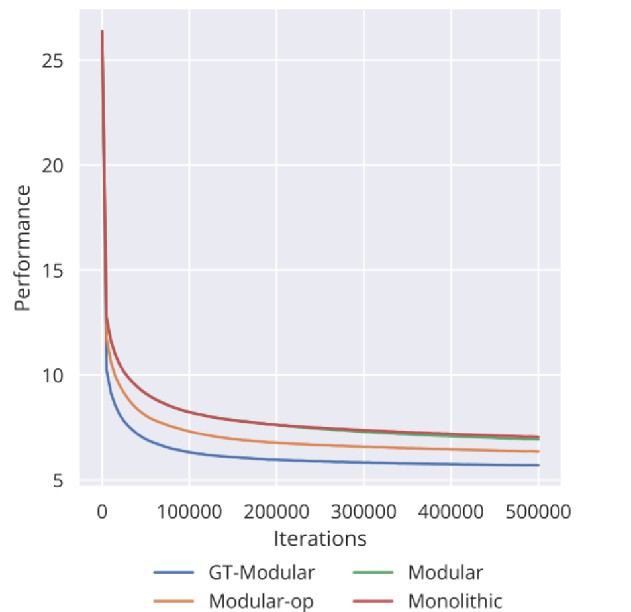
良好的专业化不仅可以带来更好的表现,而且可以更快地训练
 标准模块化模型相比单体模型优势甚微
标准模块化模型相比单体模型优势甚微- 专业化带来了实质性的好处
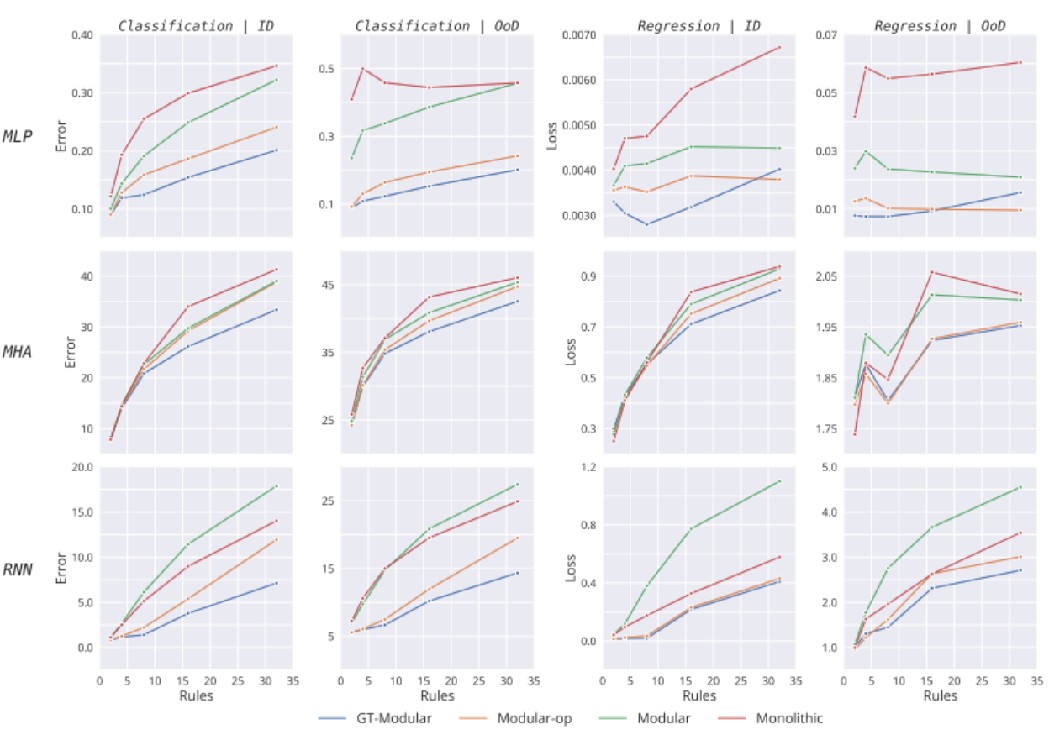
- 随着规则数量增加,专业化的优势更加明显
当前的端到端训练模块化系统既不能专注于正确的信息,也未获得最佳的专业化,因此是次优的
Collapse
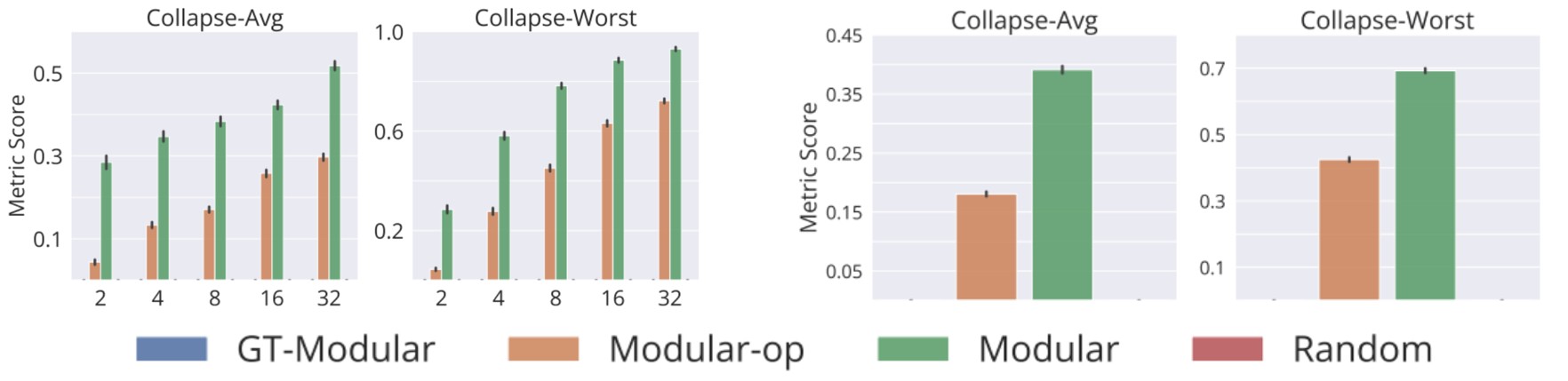
- 随机激活基线和GT-模块化系统没有任何崩溃
- Modular和Modular-op都存在崩溃问题,并且随着规则数量的增加,这个问题变得更加严重
当反向传播的任务包括找到正确的激活模式时,崩溃问题变得十分关键。这表明,需要对不同形式的正则化进行进一步的研究,以缓解崩溃问题
Specialization
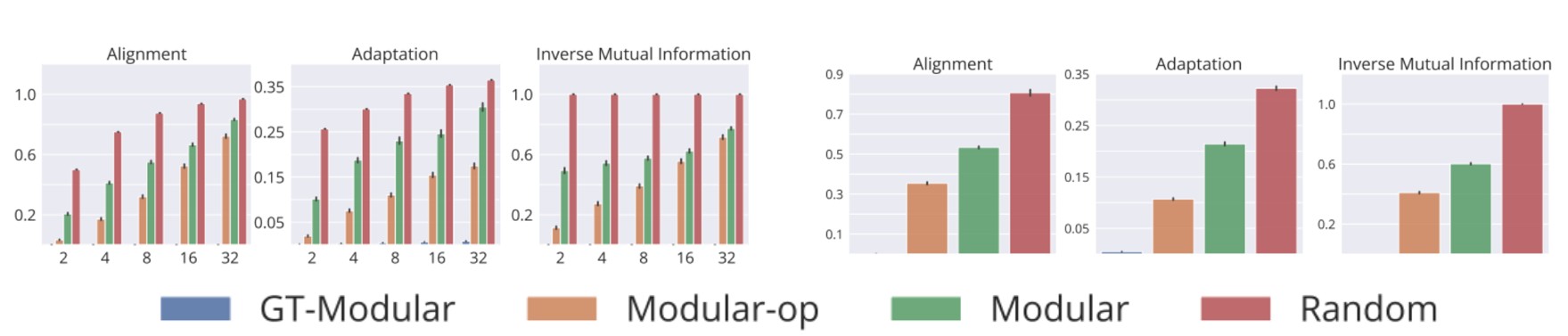
- 随机激活基线表现最差,而GT-Modular系统具最好的专业化
- 同样地,随着规则数量的增加,实现专业化变得越来越困难
- 虽然Modular-op的专业化程度略好于标准模块化系统,但与完美专业化的系统相比,仍有较大差距
Conclusion
1. 本文提供了一个适合于分析模块化系统的基准,不仅评估了系统在分布内和OoD泛化性能,还提供了在崩溃和专业化方面的评估指标。通过大规模分析,本文发现了模块化系统的许多有趣的特性,并强调了可能导致此类系统的不良表现的潜在原因。
2. 完美的专业化确实有助于提高模型性能,并且可能带来更快的训练速度,尤其是在具有较多规则的情况下(意味着更复杂的任务)。
3. 现有标准端到端训练并不能实现完美的专业化,因为真实世界的数据分布通常是复杂和未知的,我们无法拥有所有的先验知识。因此,需要额外的归纳偏置来促进模块专业化,可能的研究方案包括促进模块路由,或正则化方案或优化策略等。
- 发表于 2024-05-08 11:59
- 阅读 ( 1872 )
- 分类:论文分享
