论文分享-LANGUAGE MODELS REPRESENT SPACE AND TIME
研究动机
自从大语言模型问世以来,就表现出非凡的能力,我们的科研和工作都离不开大语言模型的帮助。大语言模型的强大功能可以为我们提供以下几种服务:文本生成、摘要总结、关键信息提取、文本分类、文本检索、文本改写等。

那么LLM表现出如此强大的功能,我们会产生一个思考:LLM真的理解了我们现实的物理世界吗?当我和大语言模型交互时,它真的能理解我的情绪感知和现实处境吗?2021年,华盛顿大学语言学家Emily M. Bender发表了一篇论文,认为大型语言模型不过是「随机鹦鹉」(stochastic parrots)。“随机鹦鹉“是什么意思呢?鹦鹉大家都知道,它模仿人类讲话,但没有掌握其真正的本质,并不理解其真正的含义和情感。随机性是指大语言模型并不理解真实世界,只是统计某个词语出现的概率,然后像鹦鹉一样随机产生看起来合理的字句。因此本文提出猜测:大语言模型表现出的惊人能力,或许只是因为它学习了大量肤浅的统计数据集合,而并不是因为它是一个包含数据生成过程的连贯模型(也即世界模型)。文本的研究主要围绕以下两个大的问题进行开展:1.语言模型是否理解了时间和空间?是否就等同于世界模型?2.LLM是否具有空间感?并且在多个时空尺度上都是如此?
研究方法
文本的研究方法实际上并不复杂,主要使用了探针技术进行实现,那么什么是探针呢?我们高中都学习过生物学中的基因探针,基因探针指的是一段带有检测标记,且顺序已知的,与目的基因互补的核酸序列。基因探针通过分子杂交与目的基因结合,产生杂交信号,能从浩瀚的基因组中把目的基因显示出来。通常应用于生物体内某种特定基因的检测,这种可能是致病基因,因此这种技术可以诊断疾病,以及进行犯罪调查等。那么总结一下:基因探针的作用实际上就是探索基因组的黑箱结构,将基因序列由未知变为已知。此时我们可以类比以下:我们将神经网络看作是一个未知的基因组,如果我们要了解神经网络中各隐层的表征是否具有输入数据的某种特性,是不是也能使用类似的探针技术?
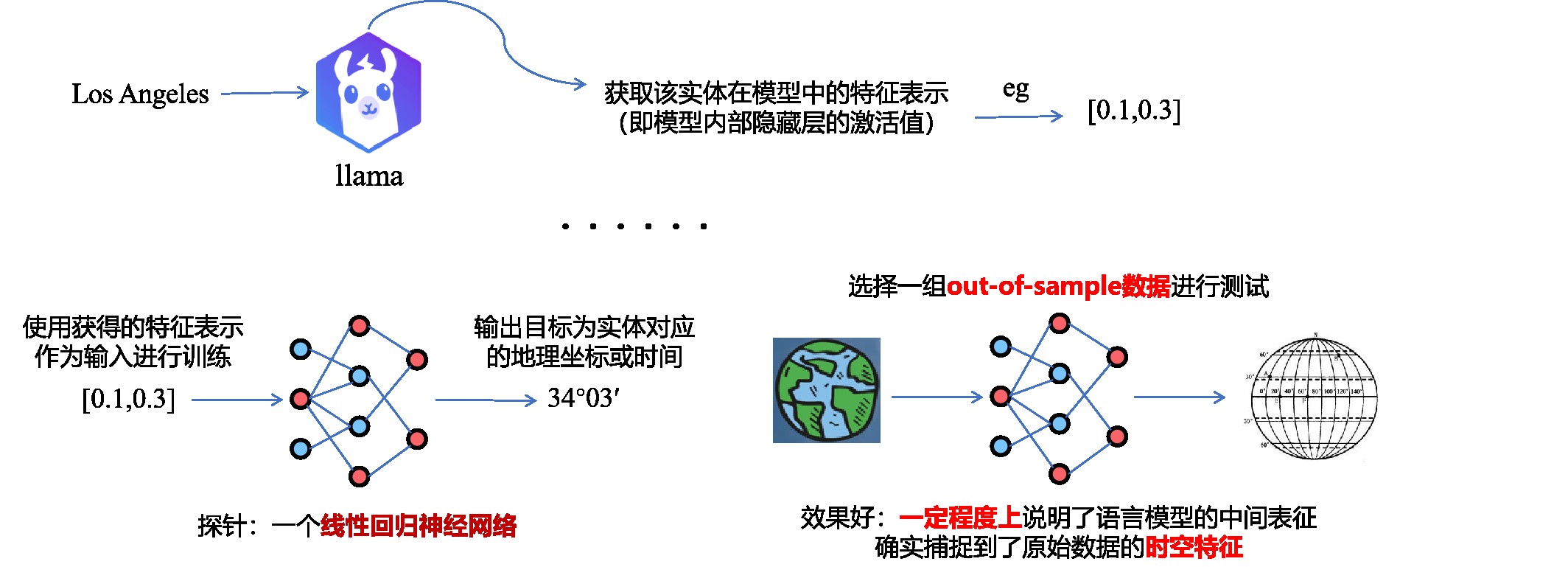
在正式的实现之前,为验证大语言模型是否真实存在对基本时间和空间概念的编码,作者首先准备了一系列的空间数据集与时间数据集,空间数据集有三个:包括世界上各个国家、州、城市、地标等地点的名称和坐标、美国各个州、城市、地标等地点的名称个坐标以及纽约市各个区、街道、地铁站等地点的名称和坐标。
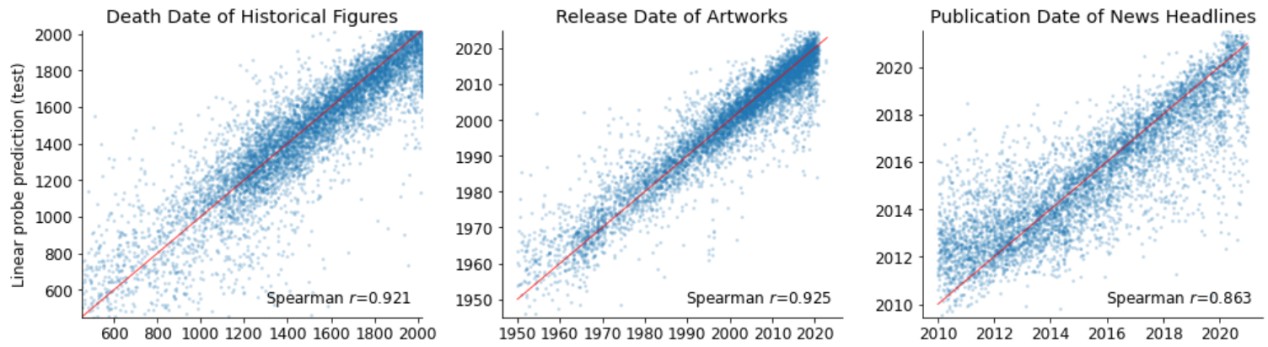
时间数据集也有三个:包括过去3000年内去世的历史人物及去世时间、1950年以来发布的歌曲、电影和书籍及其发布时间、2010年至2020年发布的新闻标题及其发布时间。数据示例如下所示:”Los Angeles””34°03′ 118°15′”第一个是洛杉矶的具体经纬度,”Abraham Lincoln” “1865”,第二个是美国总统林肯的去世时间。


接下来是具体的实现:以洛杉矶这个实体来说,作者将”Los Angeles”输入给大语言模型,本文使用的是Llama模型。从中获取该实体在模型中的特征表示,也就是在神经网络内部隐藏层的激活值,这个特征也就是向量的形式。按照这样的步骤获取一组特征值之后,作者使用这组特征值作为输入,以实体对应的地理坐标或时间作为输出对一个线性回归神经网络进行训练,那么这个神经网络就是所谓的探针。当训练完成后,再使用一组测试集对探针进行测试,如果探针能够较为准确地预测出实体对应的真实经纬度或时间,那么可以认为大语言模型的中间表征在一定程度上捕捉到了原始数据的时空特征。
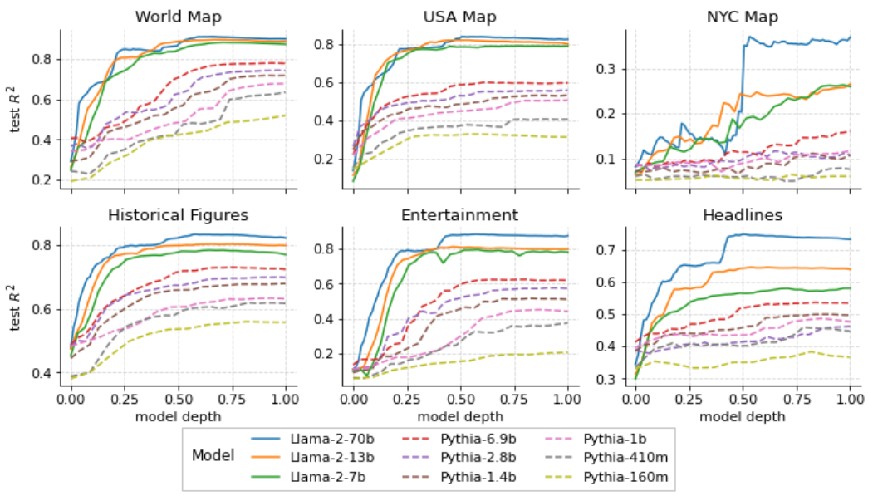
实验验证
实验的思路为研究人员使用llama2系列模型,提取了这些地点和事件在模型内部每一层的的内部激活,并使用这些激活值作为输入训练了线性回归探针,再来预测它们的真实世界位置或时间。实验结果如下图所示:横轴代表模型深度, 通俗的讲也就是说提取的是第几层的激活值。纵轴表示最终探针的预测准确率,实验结果揭示了模型在整个早期层构建空间和时间表征的证据,然后在模型中点附近达到稳定状态,这个过程的结果在较大的模型的表现始终优于较小的模型。
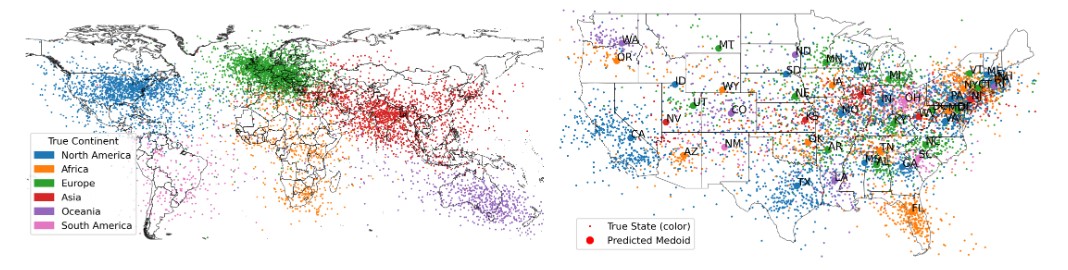
除此之外,作者还进行了一系列的鲁棒性实验。这些鲁棒性实验进一步证明了这些中间表征是线性的,因为当使用非线性的探针时表现不佳。第二个是语言模型对提示的变化有很高的鲁棒性,这是什么意思呢?就是说当提示为输出Los Angeles的经纬度或者是我想知道Los Angeles的精确经纬度,语言模型对于Los Angeles这个token的中间表征是几乎不变的。第三个是不同类型的概念之间的表征是相似的,例如,城市和自然地标之间是相近的。除此之外,作者还进行了一些创新性实验,用探针来寻找作为空间或时间函数激活的单个神经元,提供强有力的证据证明该模型确实使用了这些特征。什么意思呢?我的理解是作者使用探针技术来检测究竟是哪个神经元才是真正进行特征表示的那一个神经元。
思考与感悟
根据图灵奖获得者、Meta的首席AI科学家Yann LeCun的定义,一个世界模型应该包含以下元素:1)观察 x(t):这是你在给定时刻对世界的看法或感知。想象你在玩视频游戏,看到你的角色站在一个平台上。那就是你的观测。2)状态估计 s(t):模型对当前世界状态的估计。就像你在游戏中有一个关于一切所在位置的心理地图,即使你现在看不到全部。3)动作建议 a(t):模型可能提出的行动方案。这是对下一步要做什么的建议,比如决定跳跃到另外一个台阶上。
4)潜在变量建议 z(t):用于表示当前观察不能完全解释的未知信息。这就有点棘手了。它代表所有未知因素,这些因素可能影响你行动的结果。想象游戏中有风,当跳跃时风可能会把你的角色吹偏。你看不到风(它是未知的),但你知道它可能影响你的跳跃。Yann LeCun认为,世界模型有两个组成部分:编码器(这个函数接受你的观测并将其转换成模型可以更有效工作的格式或表示),和隐藏状态预测器【利用编码后的观测、当前的世界状态、你正在考虑的行动和未知因素(潜在变量)来猜测接下来会发生什么,以此来预测世界的未来状态】。Yann LeCun定义下的世界模型之所以强大,是因为它试图模仿智能生物与世界的互动方式:观察、理解、预测和行动,同时也考虑未知的事物和因素。它是一个综合框架,可以应用于从玩视频游戏到导航现实世界环境的各种问题,目标是创建能够学习以对未知因素具有适应性和鲁棒性(在异常和危险情况下系统生存的能力)的方式导航和与复杂环境交互的模型。
LLM对时间和空间的表示是线性的和低维的,并没有构建出对整个世界的内在物理规律的建模,二者概念存在显著差异。LLM与真正意义上的World Model相距甚远,本文更多在探索语言模型内部是否存在对基本时间和空间概念的编码,关注大模型的可解释性。本文从预训练的大语言模型中提取了实体的特征表示,再利用该特征作为输入训练一个线性回归模型,将这些特征映射为经纬度和时间,映射质量取得了不错的效果。可以证明大语言模型的中间层与预期预测中存在某种映射关系,但不能证明大语言模型能感知时间和空间。大语言模型与世界模型差距甚远,即便是text-video模型sora,也不能称之为world model。
- 发表于 2024-05-08 22:15
- 阅读 ( 1003 )
