深度学习编译器介绍——前端编译
深度学习编译器需要理解输入的源程序并将其映射到目标机。为了实现这两项任务,编译器的设计被分解为两个主要部分:前端和后端。
本节部分内容摘自https://openmlsys.github.io/
深度学习编译器需要理解输入的源程序并将其映射到目标机。为了实现这两项任务,编译器的设计被分解为两个主要部分:前端和后端。前端是不感知具体后端硬件的,因此前端执行的全部都是与硬件无关的编译优化。
前端的主要功能:解决编译生成的中间表示的低效性,使得代码的长度变短,计算图更简洁,编译与运行的时间减少,执行期间处理器的能耗变低。前端流程可以用下图表示:

传统中间表示如LLVM IR,能够很好地满足通用编译器的基本功能需求,包括类型系统、控制流和数据流分析等。然而,它们偏向机器语言,难以满足机器学习框架编译器的中间表示的需求。因此出现了大量支持自动微分等深度学习特有功能的中间表示,如TorchScript IR、XLA HLO和MLIR等。
前端编译优化的方法有很多,机器学习框架也有很多不同于传统编译器的优化方式,包括无用与不可达代码消除、常量传播和常量折叠、公共子表达式消除。
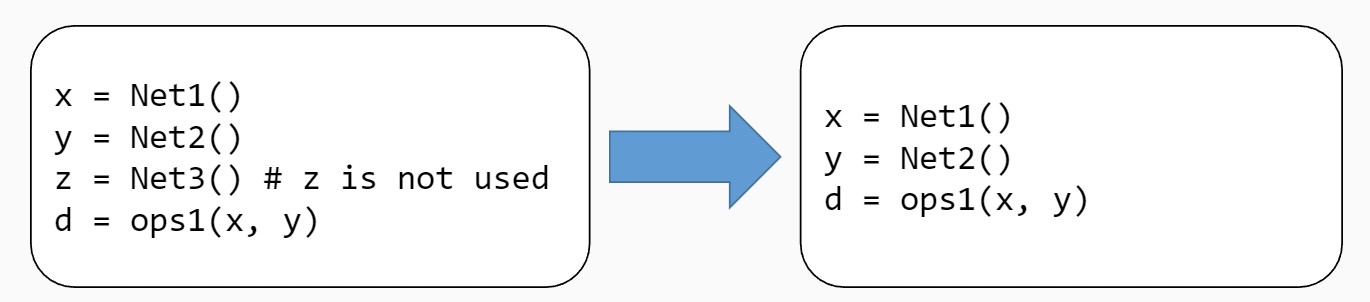
无用与不可达代码消除:无用代码是指输出结果没有被任何其他代码所使用的代码。不可达代码是指没有有效的控制流路径包含该代码。删除无用或不可达的代码可以使得中间表示更小,提高程序的编译与执行速度。无用与不可达代码一方面有可能来自于程序编写者的编写失误,也有可能是其他编译优化所产生的结果。
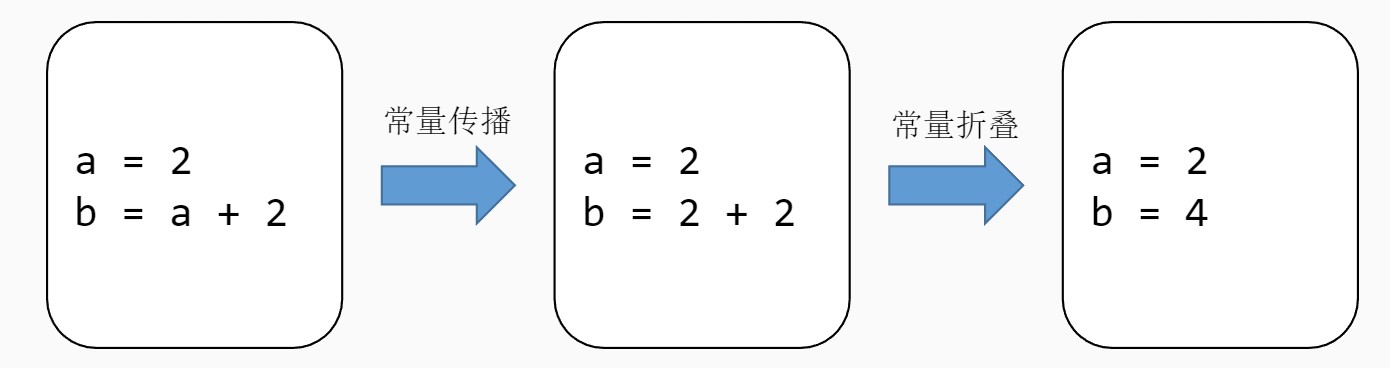
常量传播:如果某些量为已知值的常量,那么可以在编译时刻将使用这些量的地方进行替换。
常量折叠:多个量进行计算时,如果能够在编译时刻直接计算出其结果,那么变量将由常量替换。
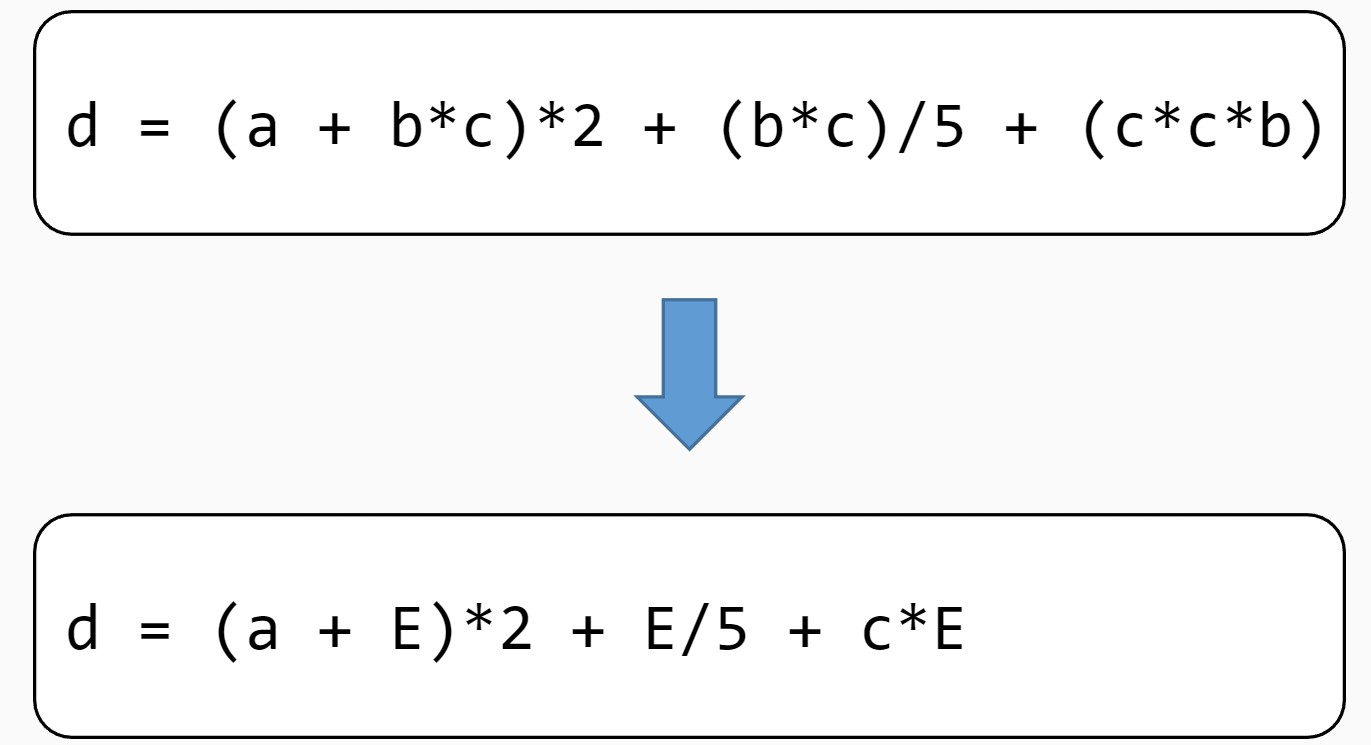
公共子表达式消除:如果一个表达式E已经计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E就成为了公共子表达式。对于这种表达式,没有必要花时间再对它进行计算,只需要直接用前面计算过的表达式结果代替E就可以了。
- 发表于 2022-11-09 22:15
- 阅读 ( 1646 )
- 分类:边端协同深度计算
