四足机器人&&强化学习(一)
仅本体感知
ETH 2020 --Learning quadrupedal locomotion over challenging terrain
这篇工作的主要特点是仅利用了四足机器人的本体信息(proprioceptive feedback),使用强化学习进行仿真环境训练和 zero-shot 的 sim-to-real 真实环境迁移,得到了能够在许多 challenging terrain 上成功的行走策略。
本文的主要贡献包括以下几个部分。
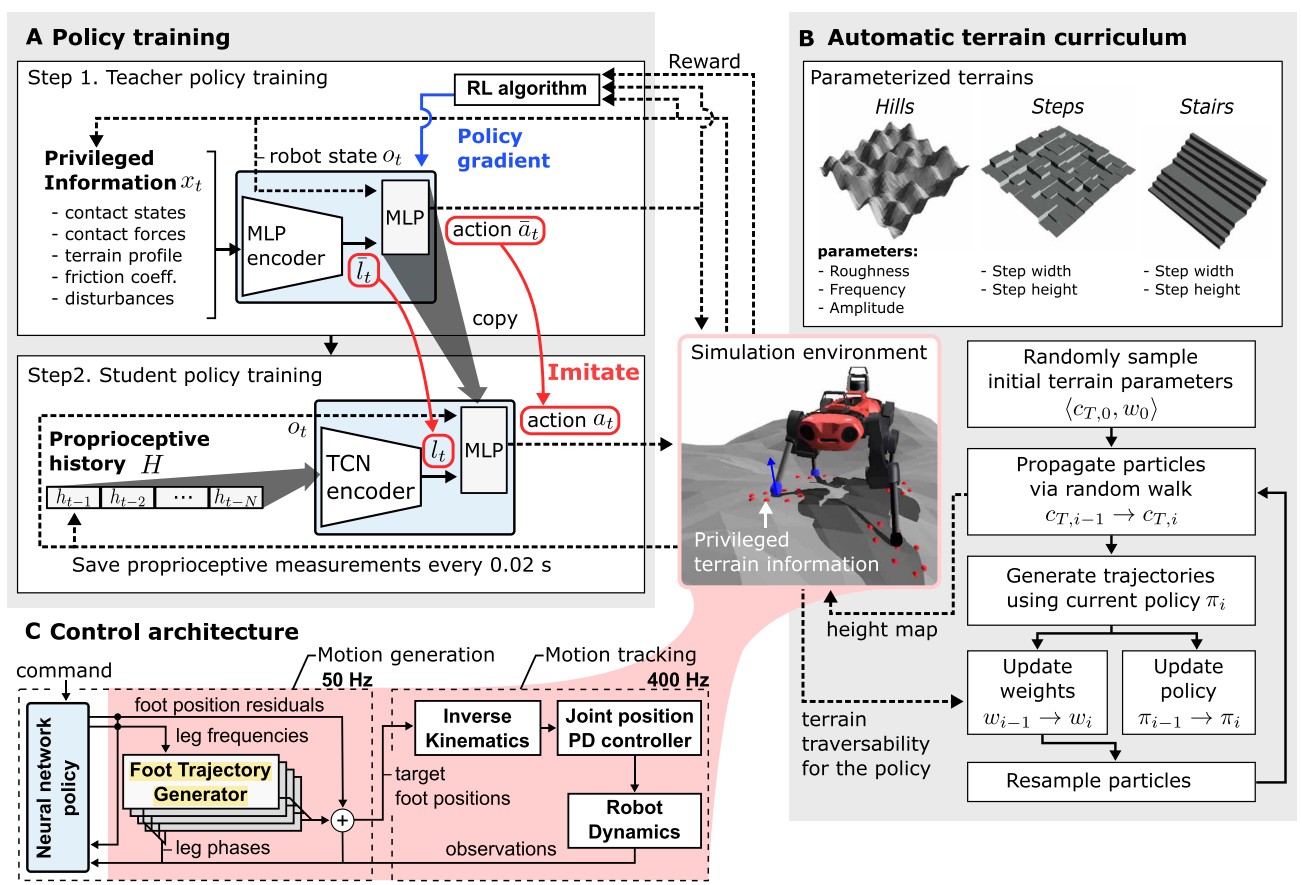
Domain Randomization & Adaptive Terrain Curriculum
之前的许多工作需要对真实物理环境的状态转移进行准确建模,而这一建模往往是很难的。本文使用了domain randomization 的方法来对模拟器中的物理参数进行 randomize,从而使策略能够更加容易的从仿真器到真实世界中进行迁移。另外在训练中使用了 Adaptive Terrain Curriculum,逐步的改变四足训练的地形参数,从简单的地形开始来使四足不断学习到新的技能,并泛化到新的环境中。
Privileged Learning
直接从真实环境信息中训练策略是不可行的,原因是(1)真实环境中噪声很大;(2)真实环境中无法获得地形信息的真值。特别的,本文的假设是只利用本体信息,不使用视觉和雷达(Blind Setting)。
Privileged Learning 将四足的训练过程分为两个部分:
在第一阶段,使用仿真器中能够获得 Ground Truth 信息训练一个 Teacher Policy。由于该策略在使用完美信息的情况下进行训练,故而能够在很快的时间内达到一个很好的水平。然而,该策略并不能用于真实环境,原因是真实环境下无法获得这些 Ground Truth 信息。在本文中,Ground Truth 信息包括四足周围的地面高度图,contact信息和四足本体信息。Teacher 策略使用 TRPO 策略梯度法进行训练。
在第二阶段,使用 teacher forcing 的方法训练一个 student 策略,其中 student 策略只能获得四足在实际中使用的本体信息。在相同状态下,student 策略使用本体信息作为输入,而对应的 teacher策略使用 gound truth 作为输入;student 的损失函数设定为模仿 teacher 的动作,使用监督学习的方法进行训练。
Student策略使用 Temporal Convolution Network (TCN)网络。使用时序卷积网络TCN来对历史信息进行处理,从而能够获得更长时间的历史信息。特别的,TCN 能够从历史信息中推断contact和slip的有关信息。
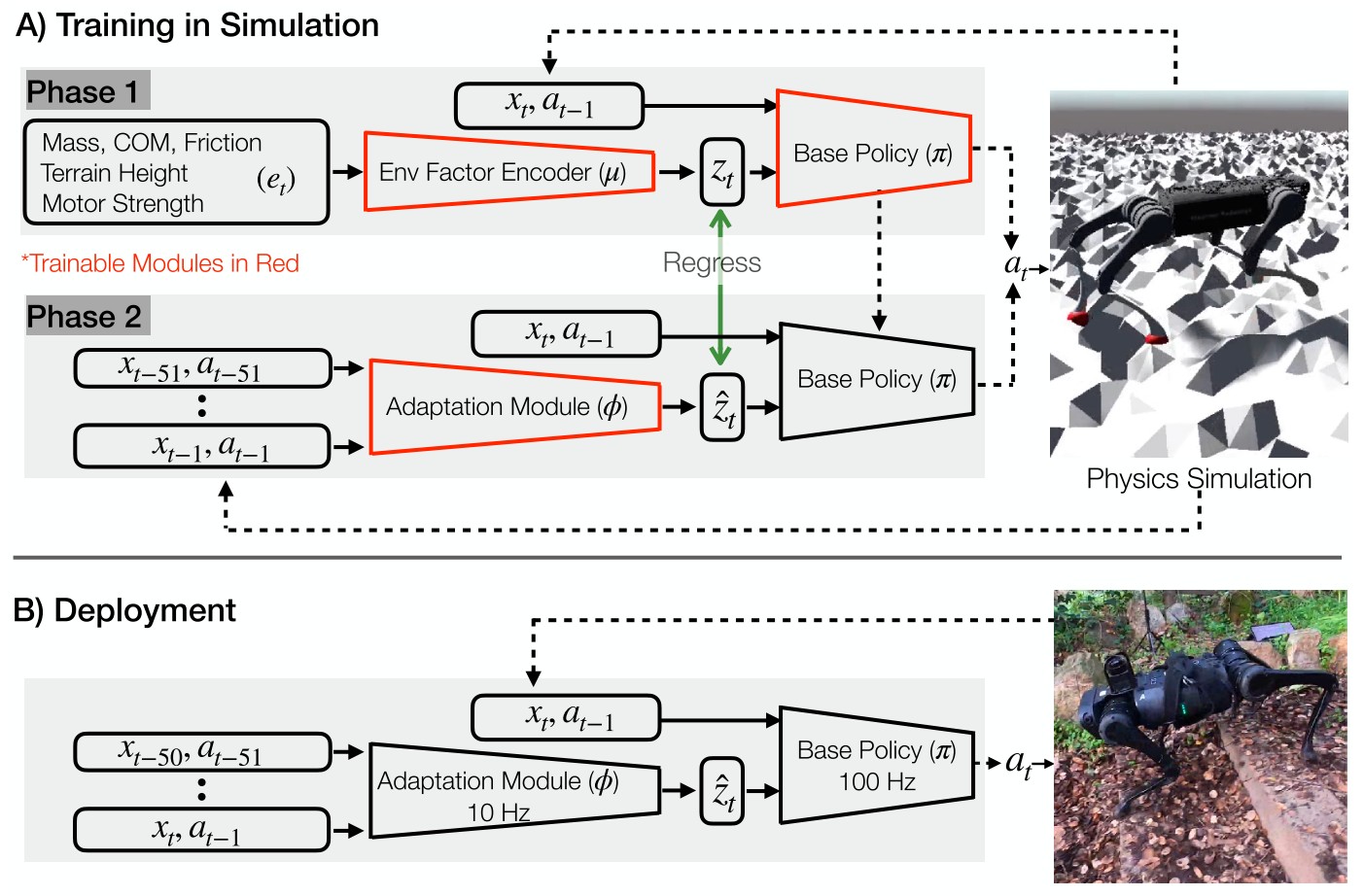
UC Berkeley 2021 -- RMA: Rapid Motor Adaptation for Legged Robots

以往的四足机器人要么已经针对它们所要适应的环境进行了完全手动编码,要么通过手动编码和学习技巧的结合来教它们在环境中导航。与这些不同,RMA 是首个完全基于学习的系统,通过探索并与世界进行交互,使腿式机器人能够从头开始适应环境。
文章提出了快速电机自适应 (RMA) 算法来解决四足机器人的实时在线自适应问题。RMA 由两个组件组成:基本策略和适配模块。这些组件的组合使机器人能够在几分之一秒内适应新情况。RMA 在不使用任何领域知识(如参考轨迹或预定义的足部轨迹生成器)的情况下完全在模拟中进行训练,并且无需任何微调即可部署在 A1 机器人上。
研究者在各种地形生成器上训练 RMA,包括乱石滩、泥地、不平整草地、混凝土地、鹅卵石地、石阶和沙滩等。结果表明,RMA 在不同的现实环境和模拟实验中都实现了优于其他腿式机器人的性能。
ETH 2022 -- Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
利用NVIDIA设计的并行仿真环境,可以支持数千个机器人同时的在线训练,从而在很短的时间内学习到稳定的策略,并通过sim-to-real将策略迁移到真实的环境中。

主要的设计点包括:
算法可以适用于不同的四足: ANYmal B, ANYmal C with an attached arm, and the UnitreeA1 robots
Curriculum Learning: 在训练中包含了不同的地面情况,如flat, sloped, randomly rough,discrete obstacles,and stairs等,在训练中,从简单的地形开始训练,随后扩展到复杂的地形,例如提升台阶的高度 (5cm~20cm) 。
RL Formulation: 状态空间Q (base linear and angular velocities, measurement of the gravity vector, joint positions and velocities, the previous actions selected by the policy and finally, 108 measurements of the terrain sampled from a grid around the robot's base) 动作空间 (desired joint positions sent to the motors, then a PD controller produces motor torque) .
奖励设计: (1) 达到固定方向的速度 follow the commanded velocities,同时避免其他方向的速度; (2) penalize joint torques, joint accelerations, joint target changes (3) 避免碰撞: 通过检测 contacts with the knees, shanks or between the feet and a vertical surface(4) 其他: encouraging the robot to take longer steps.
Sim-to-Real: 使用 domain randomlization,包括地面摩擦力,状态噪声,机器人在周期的初始位置等
- 发表于 2023-02-06 17:56
- 阅读 ( 4296 )
- 分类:群智协作增强机理
