场景自适应的在线多视图融合视频摘要方法研究 -- 相关工作分析(2)
四、Online adaptation of RL
(一)场景自适应
不同文章怎么定义场景
《Deep Reinforcement Learning for Automated Radiation Adaptation in Lung Cancer》
- 目标:根据历史治疗计划,为非小细胞肺癌(NSCLC)患者制定自动化放射适应协议,以最大限度地提高肿瘤局部控制率,降低放射性肺炎2级(RP2)发病率
- 场景:每个病人的特征不同,根据每个病人的特点调整放射剂量以改善治疗结果【不同患者】
《Real-world Video Adaptation with Reinforcement Learning》
- 目标:通过调整视频比特率来优化视频的体验质量(QoE),以适应底层网络条件【使用RL自动学习高质量的自适应比特率(ABR)算法】
- 场景:不同客户端网络吞吐量、回放缓冲区占用不同
《Meta Reinforcement Learning for Sim-to-real Domain Adaptation》
- 目标:在不精确的动力学上训练的模型可以适应现实世界的环境,以弥补潜在的建模误差
- 场景:考虑那些严重依赖于环境的动态参数的任务(在未知摩擦力下将冰球射到目标位置的任务)
《zTT: Learning-based DVFS with Zero Thermal Throttling for Mobile Devices》
- 场景:
【应用层面】在运行手机游戏时,由于不同游戏对CPU和GPU的需求不同,它们的能量分配也需要相应改变。例如,在处理图形任务时,分配给GPU的资源比分配给CPU的资源更有效。分配过多的功耗给CPU或GPU都会不必要地增加功耗和系统温度
【运行环境】移动设备会经历更复杂的热环境,例如用户移动性、保持方法和外部温度
《VCMaker: Content-aware configuration adaptation for video streaming and analysis in live augmented reality》
- 目标:自适应地学习最佳视频配置,实现高精度,低延迟和低能耗对象检测AR应用
- 场景:带宽的可变性,目标物体的时移移动速度,以及相邻帧之间的相似性(摄像头固定,连接wifi)
(二)任务自适应
个性化视频摘要
目标类型
兴趣内容
摘要长度
五、RL accelerates convergence on mobile devices
RL中一个众所周知的挑战是信用分配问题,即奖励是稀疏的或暂时延迟的,因此很难将每个行动与奖励联系起来。由于只有全局可识别性奖励,我们的DQSN也存在这个问题,因为只有在一系列完整的行动之后才能生成单一的全局奖励,这不可避免地减慢了模型的收敛速度。【设计密集的奖励】
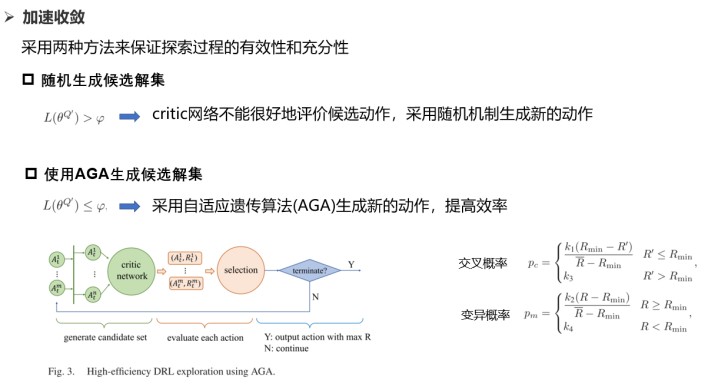
1)高效探索
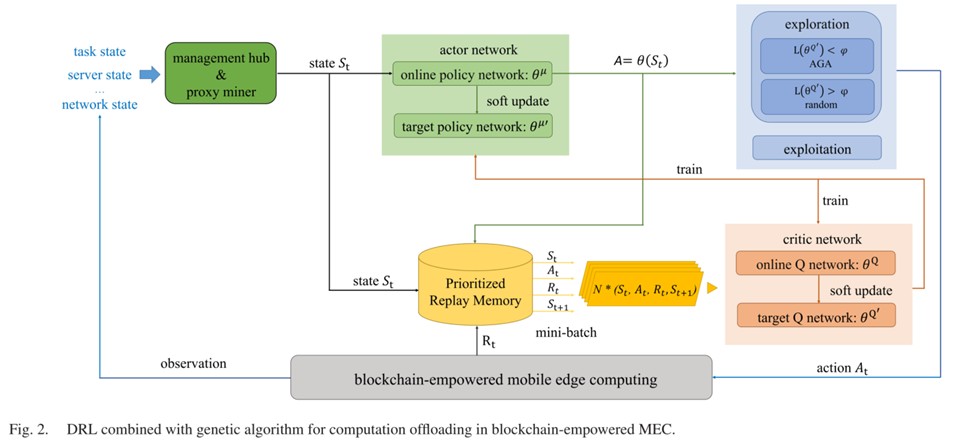
《Online deep reinforcement learning for computation offloading in blockchain-empowered mobile edge computing》
【与本文的区别】:此文解决的是高维动作空间导致模型收敛缓慢,本文的动作空间是有限的,是由高维的状态空间引起
2)知识迁移
《zTT: learning-based DVFS with zero thermal throttling for mobile devices》
采用迁移学习和使用历史数据的样本副本
基于迁移学习的方法:这背后的想法是,即使环境发生变化,整个神经网络参数也只有少数会发生变化,因为模型的结构可能本质上是相似的。在实验中验证了基于DQN的算法在具有基本相同的神经网络参数(包括相同的输入和输出层,以及更新较小的参数)的变化环境中工作得相当好。
使用历史数据样本副本
实验方法:
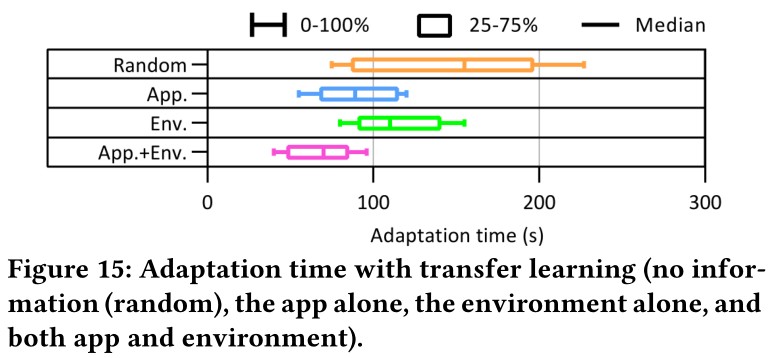
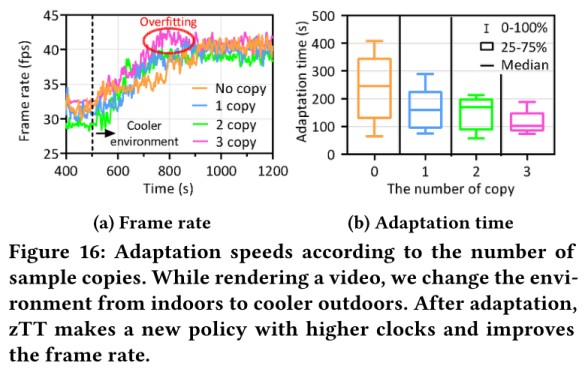
基于迁移学习的方法:目的: 探讨迁移学习在减少适应时间方面对 jetson tx2的影响。图15显示了通过迁移学习附加知识(即,单独的应用程序、单独的环境以及应用程序和环境)来改善适应时间。结果表明,随着知识的增加,学习时间显著减少。
使用历史数据样本副本:(1)验证副本数量的影响。在replay memory中复制特定的样本可以提高样本效率,但是由于所谓的样本不平衡问题会导致过拟合。(2)验证方法的有效性。结果表示即使只有一个样本拷贝,适应时间也减少了一半。
《Multi-agent Reinforcement Learning Improvement in a Dynamic Environment Using Knowledge Transfer》
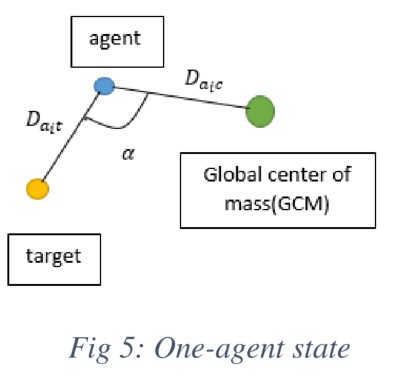
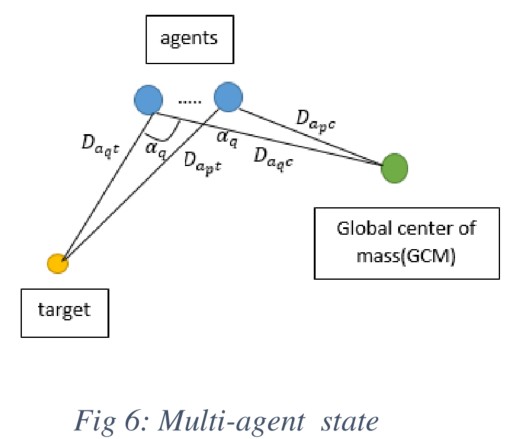
抽象状态空间+迁移Q-table
利用状态抽象,可以忽略状态空间中不相关的特征,减少状态空间的大小
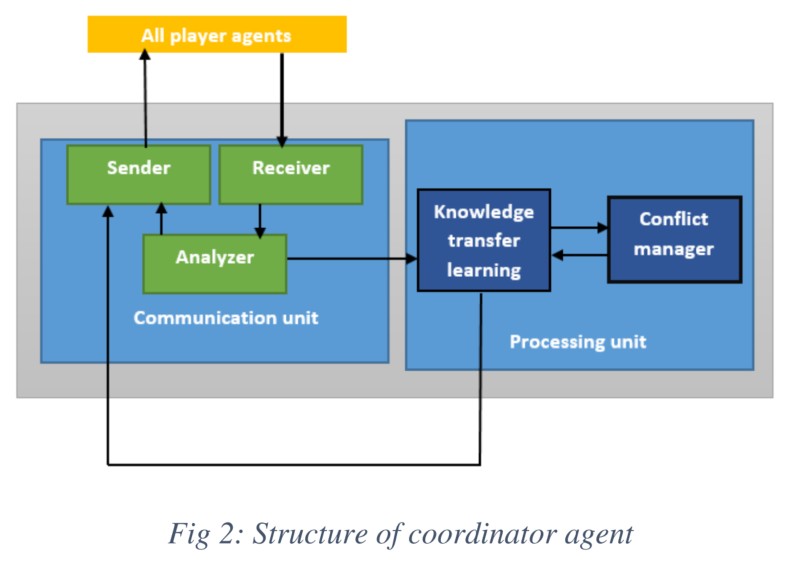
知识结合与迁移
在每个时间步长结束时,所有agent将它们的Q-table发送给协调agent,更新Q-table。
在冲突管理单元中,每个q值在新表中的表示(加权平均、M为出现频次):
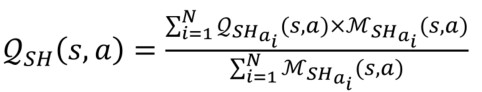
现有只考虑提高RL收敛速度,我们考虑终端收敛速度
- 发表于 2023-02-22 16:02
- 阅读 ( 1671 )
- 分类:边端协同深度计算
