TinyAgent: Function Calling at the EdgeTinyAgent: Function Calling at the Edge
TinyAgent: Function Calling at the Edge
摘要:
近期的大语言模型(LLMs)使得可以开发出能够通过调用功能来整合各种工具和API,以完成用户查询的高级智能体系统。然而,这些LLMs在边缘的部署尚未被探索,因为它们通常需要基于云的基础设施,这是由于它们庞大的模型尺寸和计算需求。为此,我们提出了TinyAgent,一个端到端的框架,用于训练和部署能够调用功能的特定任务小型语言模型智能体,以在边缘驱动智能体系统。我们首先展示了如何通过LLMCompiler框架启用开源模型的准确功能调用。然后,我们系统地策划了一个高质量的功能调用数据集,我们使用这个数据集对两个小型语言模型进行了微调,即TinyAgent-1.1B和7B。为了高效的推理,我们引入了一种新颖的工具检索方法来减少输入提示的长度,并利用量化进一步加速推理速度。作为一个驱动应用,我们展示了一个本地类似Siri的系统,用于苹果的MacBook,可以通过文本或语音输入执行用户命令。我们的结果表明,我们的模型能够实现,甚至超越像GPT-4-Turbo这样的大型模型的功能调用能力,同时完全在边缘部署。我们开源了我们的数据集、模型和可安装的包,并为我们的MacBook助理智能体提供了演示视频。
引言:
LLM 通过普通语言(例如英语)执行命令的能力使Agent系统能够通过协调正确的工具集来完成用户查询。
现有的大模型参数量较大,因此难以在本地端部署。LLM模型主要在云端部署,对于用户而言,上传的云端数据带来隐私泄露的问题,此外对于现实环境而言,数据链接的不稳定性会导致延迟响应等问题。
与此同时,大模型会留存一些关于世界的通用参数信息,即”涌现能力”,但这类信息对于下游任务而言可能非必须。
关键问题:一个拥有明显较少参数记忆的小型语言模型能否模拟这些大型语言模型的这种涌现能力?
在这项工作中通过使用专门的、高质量的数据训练小型模型,而不需要回忆一般的世界知识。我们的目标是开发可以在边缘安全和私密地部署的小型语言模型(SLM),同时保持理解自然语言查询和协调工具和API以完成用户命令的复杂推理能力。
为了实现这一点,本文首先探索了使小型开源模型执行准确功能调用的方法,这是智能体系统的关键组成部分。现成的小型模型通常缺乏复杂的功能调用能力,需要微调。接下来,本文讨论了系统地策划用于训练这些小型模型的高质量功能调用数据集,使用专门的Mac助理智能体作为本文的主要应用。本文展示了在这个策划的数据集上对模型进行微调可以使SLMs超越GPT-4-Turbo的功能调用性能。最后,使用一种新颖的工具RAG方法和量化来提高这些微调模型的推理效率,允许在边缘进行高效的部署和实时响应。
相关工作:
函数调用的LLM
LLM 的复杂推理能力使其能够调用函数(即工具)。 这使 LLM 能够使用外部函数(例如计算器或搜索引擎)来提供比直接响应更准确的用户查询答案。
Toolformer ,它启发了各种工具调用框架 Gorilla 和 ToolLLM 证明,可以对开源 LLM 进行微调,以在各种现实世界用例中获得函数调用功能Octopus 引入了调用软件 API 的设备上 LLM。TinyAgent 通过启用通过并行函数调用 以及一种新颖的工具检索方法来实现高效推理。 此外,本文的方法不需要任何架构更改,使其与更广泛的开源模型兼容。
数据集合成
为了解决没有足够数据集进行微调的问题,使用LLM合成新的训练数据集。生成式数据集虽然有很好的效果,但生成的新训练数据集会过大。通过过滤大的数据集生成小的数据集实现高效的训练和模型稳健的性能。TinyAgent 基于这些工作,构建了一个管道,系统地生成高质量的、特定于任务的函数调用数据集,即使使用更小、更精心策划的数据集,也能确保高效的训练和稳健的性能。
设备控制
现有的设备控制Agent方案主要关注模拟环境中的移动设备交互,但没有解决为移动设备上部署小型语言模型的问题TinyAgent 通过将设备控制公式化为高级函数调用问题,而不是低级 UI Agent操作,利用特定于任务的抽象,从而实现了更强大、更高效的命令执行
TinyAgent:
本文的研究目标是开发小型语言模型 (SLM),这些模型可以在边缘安全私密地部署,同时保持复杂的推理能力,以理解自然语言查询并协调工具和 API 来完成用户命令。
探索使小型开源模型能够执行准确的函数调用,这是Agent系统的一个关键组成部分。
主要关注的是 AI Agent将用户问询转换为一系列函数调用以完成任务的应用。 在此类应用中,模型无需自行编写函数定义,因为函数(或 API)大多是预定义的,并且已经可用。 因此,模型需要做的是确定 (i) 要调用的函数,(ii) 对应的输入参数,以及 (iii) 基于函数调用之间所需的相互依赖性,按正确的顺序调用这些函数(即函数编排)。
如何系统地整理高质量的函数调用数据集来训练小型模型,以专门的 Mac 助理Agent作为文章的主要应用程序。作为一种驱动应用,本文考虑了一个针对苹果 Macbook 的本地Agent系统,该系统可以解决用户的日常任务。 特别地,该代理配备了 16 种不同的功能,可以与 Mac 上的不同应用程序交互,包括:

模型需要做的就是利用预定义的API并确定正确的函数调用规划来完成给定任务为了生成任务数据集,向LLM提供函数集,并指示其生成需要完成这些任务的现实用户查询,函数调用规划和输入参数。并在函数调用规划中加入健全性审查,证明当前训练数据的可用性。
函数调用规划的确定
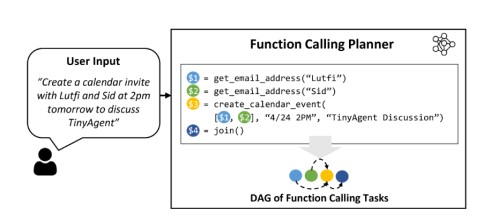
通过微调增强现有模型对函数调用的能力:TinyLlama-1.1B(instruct-32k)和 Wizard-2-7B
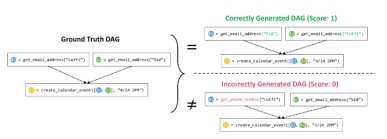
设计了一个评价指标来评估微调后模型性能:设计正确的模型规划即选择正确的函数集和正确的排列顺序。根据依赖关系构建了一个函数调用的有向无环图 (DAG),如下图所示,其中每个节点代表一个函数调用,从节点 A 到 B 的有向边代表它们的相互依赖关系(即函数 B 只有在函数 A 执行后才能执行)。 然后,比较这个 DAG 是否与Ground Truth的 DAG 相同,以验证依赖关系的准确性。
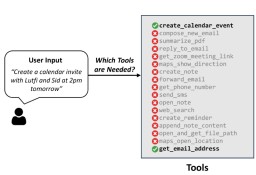
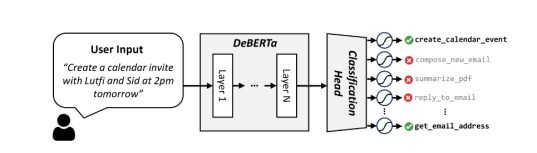
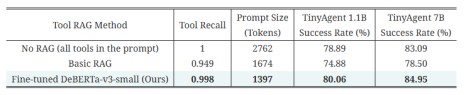
使用一种新颖的工具 RAG 方法和量化来提高这些微调模型的推理效率,从而实现高效的边缘部署并提供实时响应。主要是在Macbook本地部署TinyAgent:需要确保不仅模型尺寸小,而且输入提示尽可能简洁。为了使输入提示词尽可能减小,需要确定完成用户命令所需要的所有功能,采用了一个工具RAG来解决该问题。在训练数据上微调了一个 DeBERTa-v3-small 模型,以执行 16 路分类,如右图所示。用户查询被作为输入提供给该模型,然后将末尾的 CLS 符元通过一个简单全连接层传递,将其转换为一个 16 维向量(这是RAG工具的总大小)。 该层的输出通过一个 sigmoid 层传递,以生成选择每个工具的概率。 在推理过程中,我们选择概率大于 50% 的工具,如果满足条件,则在提示中包含其描述。
实验归纳:
通过LLM指导的数据生成,生成创建了 80K 个训练数据、1K 个验证数据和 1K 个测试数据,总成本仅为 约500 美元。后续的实验基于该数据集展开
模型选取TinyLlama-1.1B,Wizard-2-7B
定义评估指标后,使用7E-5的学习率,对模型在该数据集上进行了3epoch的LoRA微调1.1B 模型的成功率从 12.71% 提高到 78.89%,7B 模型的性能从 41.25% 提高到 83.09%,比 GPT-4-Turbo 高 4%。
针对研究内容4有效性的验证
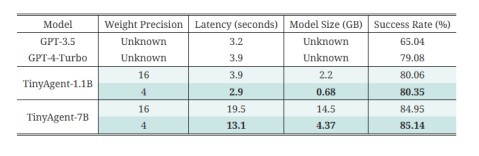
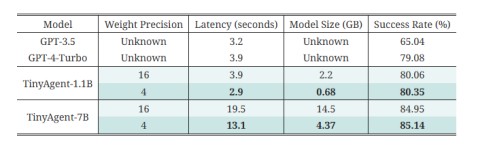
实际量化部署后,系统和GPT的模型效果对比
总结:
总结来说,我们介绍了TinyAgent,并展示了确实可以训练一个小型语言模型并用它来驱动一个处理用户查询的语义系统。特别是,我们考虑了Mac上的类似Siri的助手作为一个驱动应用。实现它的关键组件是(i)通过LLMCompiler框架教现成的SLMs进行功能调用,(ii)为手头的任务策划高质量的功能调用数据,(iii)在生成的数据上微调现成的模型,以及(iv)通过基于用户查询仅检索必要的工具的方法称为ToolRAG,以及量化模型部署以减少推理资源消耗,来实现高效部署。经过这些步骤,我们的最终模型在这项任务上实现了80.06%和84.95%的TinyAgent1.1.B和7B模型,超过了GPT-4-Turbo的79.08%的成功率。
视频演示https://www.youtube.com/watch?v=0GvaGL9IDpQ
- 发表于 2024-09-22 23:22
- 阅读 ( 2021 )
