抖音API及调用流程
抖音官方文档:https://open.douyin.com/platform/doc/OpenAPI-oauth2 调用流程包括: 第三方发起抖音授权登录请求,抖音用户允许授权第三方应用后(扫码确认或账号密码授权登录),确认通...
- 0
- 1
- Na
- 发布于 2023-02-13 22:12
- 阅读 ( 1904 )
点云入门级网络-Pointnet如何训练?(Pytorch版)
点云入门级网络-Pointnet如何训练?(Pytorch版) 1.前言 我在github上面找到了pointnet这个项目,但是由于这个项目采用的是Python 2.7, TensorFlow 1.0.1, 我是想找个基于Pytorch框架, Python3...
- 1
- 1
- Lik-
- 发布于 2023-02-05 11:22
- 阅读 ( 2166 )
如何利用卷积神经网络提取图像的特征?(Pytorch版)
1.引入库,创建一个main.py,代码如下: import torchimport torch.nn as nnfrom torch.autograd import Variablefrom torchvision import models, transformsfrom PIL import Imageimport num...
- 0
- 1
- Lik-
- 发布于 2023-02-05 00:33
- 阅读 ( 1902 )
Linux系统搭建Atari强化学习环境【Mujoco200 + Mujoco-py2.0.2.13 + gym0.15.3 + DeepMind Lab + dmc2gym】
Atari是最经典最常用的离散动作空间强化学习环境,常作为离散动作空间强化学习算法的基准测试环境。Atari可以方便地更改颜色、替换背景、增加干扰物,从而考验强化学习算法的环境适应能力。因此...
- 0
- 1
- 小方
- 发布于 2023-01-26 13:14
- 阅读 ( 3449 )
专著课程ppt下载 —— 第十二章 CrowdHMT 开放平台
一、章节介绍 介绍了人机物融合群智计算平台CrowdHMT平台 二、章节预览 三、ppt下载 提示:为了验证您的身份并确认所提供教学资源为高校教学用途,请您先用学校邮箱进行注册,待信息确认...
- 0
- 1
- Panda-admin
- 发布于 2022-10-17 15:53
- 阅读 ( 2726 )
专著课程ppt下载 —— 第七章 自学习增强与自适应演化
一、章节介绍 介绍了强化学习、深度计算方法自演化、深度计算自学习强化 二、章节预览 三、ppt下载 提示:为了验证您的身份并确认所提供教学资源为高校教学用途,请您先用学校邮箱进行注...
- 0
- 1
- Panda-admin
- 发布于 2022-10-17 15:41
- 阅读 ( 2141 )
The 'use_gui' parameter was specified, which is deprecated. We'll attempt to find and run the GUI
ros仿真时,使用urdf文件配置机器人,使用roslaunch运行,出现报错
- 0
- 1
- Ruonan
- 发布于 2022-10-08 15:08
- 阅读 ( 1584 )
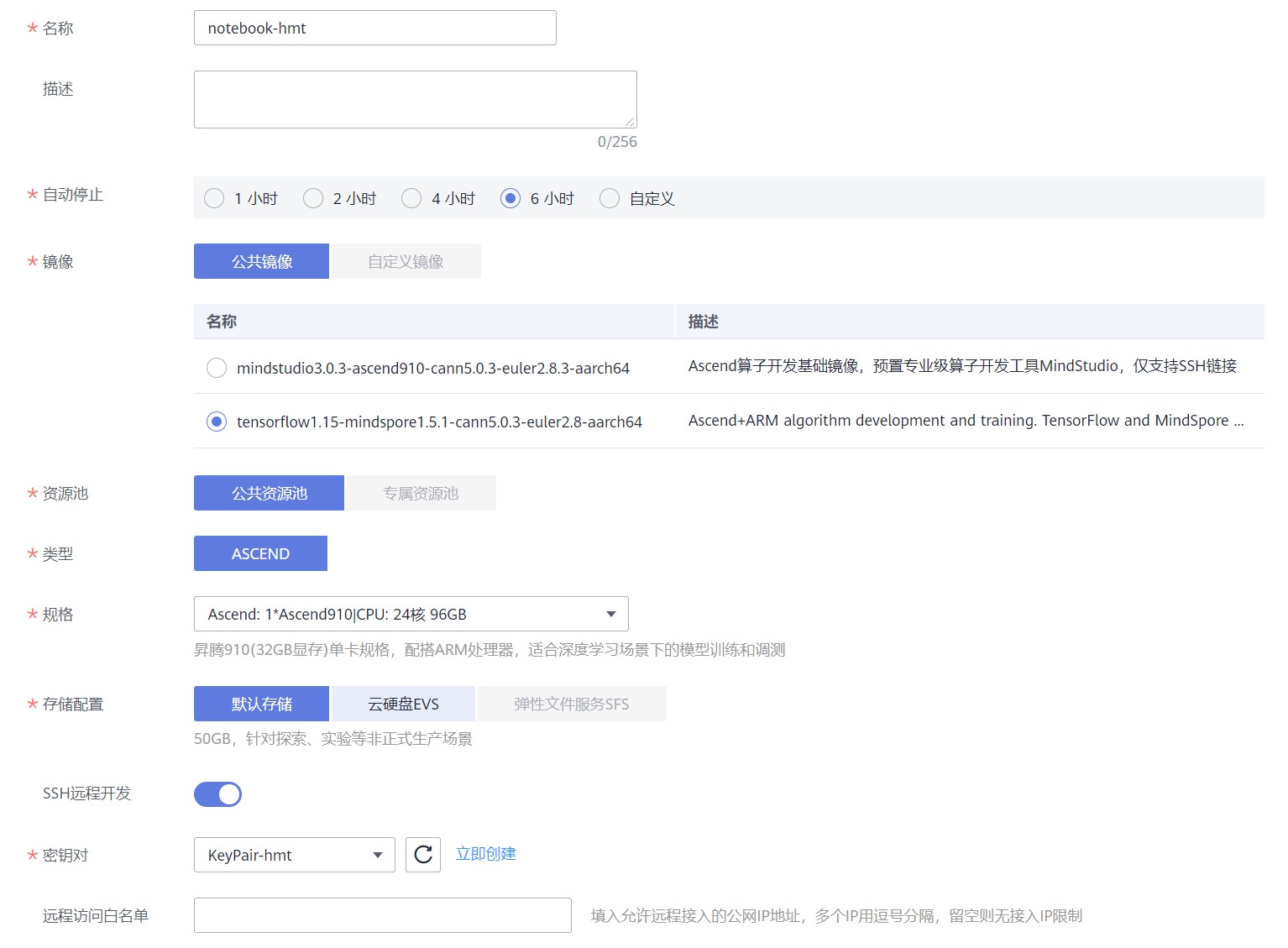
华为云管理工具ModelArts使用方法2—ModelArts使用PuTTY远程连接
1. 创建notebook创建notebook是在华为云服务器中启动一个实例,即获取一定的计算资源、内存资源以及预先定义使用的深度学习框架 2. 创建密钥或选择密钥打开密钥创建或选择一个已经存在的密钥(...
- 0
- 1
- 旺仔牛奶opo
- 发布于 2022-10-05 23:23
- 阅读 ( 2102 )
ros下xacro转换为urdf文件时出现No such file or directory:...错误时
ros下xacro转换为urdf文件时出现No such file or directory:...错误时
- 0
- 1
- Ruonan
- 发布于 2022-09-29 11:04
- 阅读 ( 2160 )
华为云管理工具ModelArts使用方法1—云服务器的使用
云服务器的使用华为云服务器是基于鲲鹏920以及910构成的昇腾训练NPU,需要使用华为提供的ModelArts云资源管理工具进行使用。ModelArts地址:https://bssconsole.yantachaosuanzhongxin.com/#/mg...
- 0
- 1
- 旺仔牛奶opo
- 发布于 2022-09-25 20:58
- 阅读 ( 1749 )
Jetson Xavier NX配置pytorch框架
针对使用pytorch官网上的安装命令为jetson板子安装好GPU版本的pytorch之后,torch.cuda.is_available()总是返回false值问题,提供为jetson板子配置深度学习框架的思路。
- 0
- 1
- 王家瑶
- 发布于 2022-07-07 11:05
- 阅读 ( 3164 )
基于Qmix的模块化机器人自重构算法(SRA)
针对二维方格形模块化机器人难以在短时间内实现快速构型转换以适应新环境和新任务的问题,提出了SRA方法,利用基于QMIX的强化学习算法使机器人通过训练获得自重构的能力,学习到构型与构型之间...
- 0
- 1
- Panda-admin
- 发布于 2022-05-24 09:35
- 阅读 ( 1943 )
分布式实时自适应分割方法DiRAP
DiRAP由存算一体的角度,综合考虑实时自适应的深度学习推理框架。面对动态情境,精细化设计分割决策空间,以降低卸载决策时延;模型动态切换时,自适应增量式加载深度模型,降低加载时延及冗余资源消耗。
- 0
- 1
- LH
- 发布于 2022-05-23 17:16
- 阅读 ( 2514 )
多智能体系统场景下的分层内在奖励机制
本文主要针对部分可观测、奖励稀疏的多智能体系统场景,解决多智能体强化学习算法收敛困难,智能体策略水平低下(lazy agent)的问题:设计了一种分层的内在奖励机制(HIRM),核心在于基于分层机制实现智能体内在奖励的平衡
- 0
- 1
- LH
- 发布于 2022-05-22 09:48
- 阅读 ( 2799 )
边端融合增强的模型压缩算法(X-ADMM)
为保证深度学习模型的预测精度,通常不能对其进行十分彻底的压缩,这导致压缩后的模型可能仍然不能顺利部署在嵌入式设备上。X-ADMM方法融合了模型剪枝和分割的优势,首先采用结构剪枝的方式并基...
- 0
- 1
- hcshen
- 发布于 2021-07-12 11:44
- 阅读 ( 2086 )